
Kafka Beyond the Basics: Exploring Internals and Overcoming Production Hurdles
In the ever-changing world of software development, Apache Kafka has become a household name, with a critical role in how organizations manage and stream data in real-time. Its rapid adoption speaks volumes about its capabilities; however, with great power comes great responsibility, particularly when it comes to scaling.
Scaling Kafka can be difficult, resulting in performance bottlenecks and operational issues that can overwhelm even the most experienced engineer. So in this discussion, our primary focus will be on the practical challenges that arise in production environments and the strategies to navigate them effectively.
Whether you’re new to Kafka or ready to tackle its more challenging aspects, this blog is here to help you get a better grip on it. We will touch on the basics to get everyone on the same page, but the real focus is on tackling Kafka’s complexities and the scaling headaches you face in the real world.
Why Kafka?
Consider a system without Kafka or any other messaging / pub-sub (publish-subscriber) model; each application must communicate directly with other applications, resulting in a complex grid of connections. This will become more complex as more applications are added to the system.
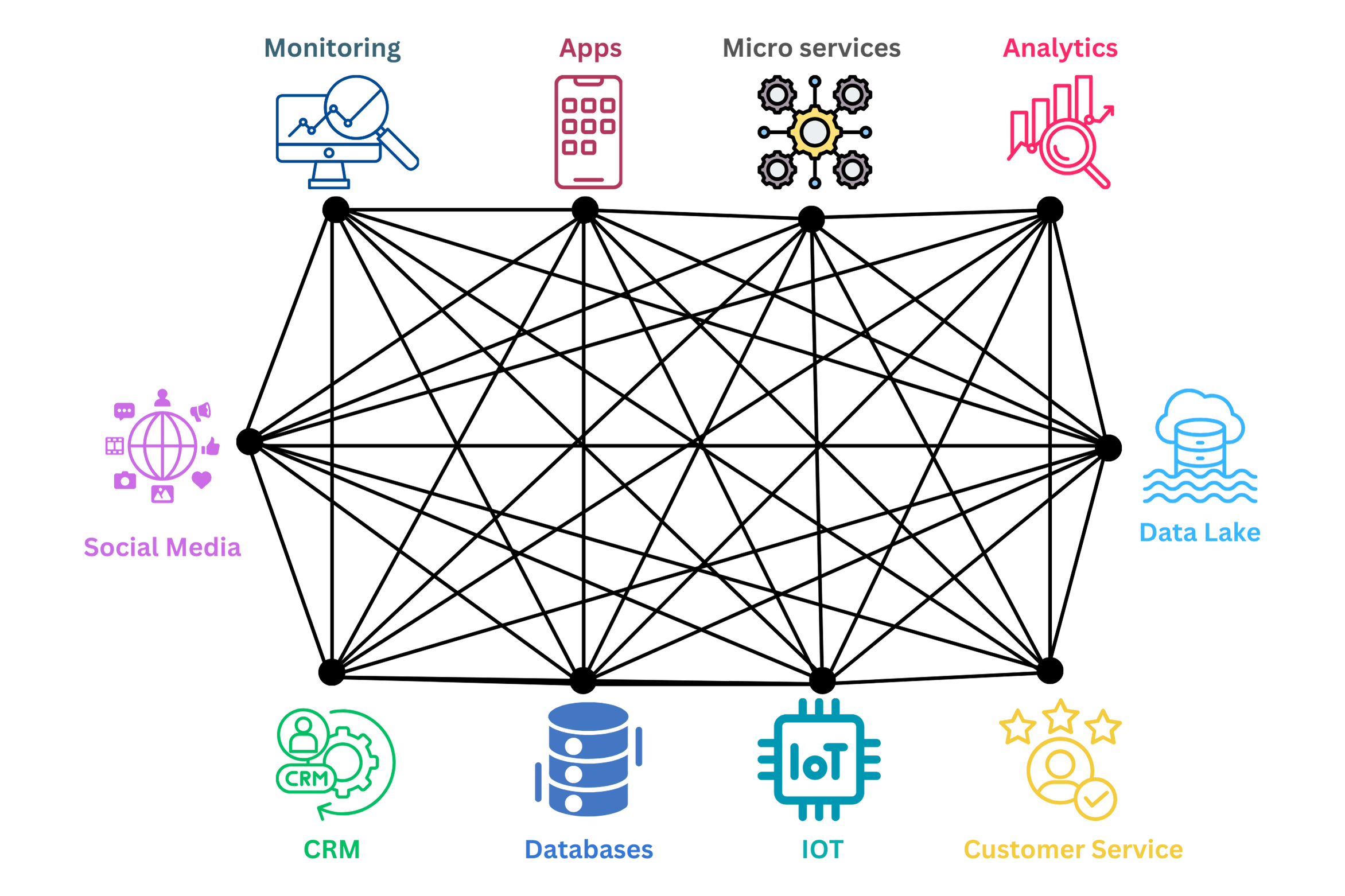
In this way, each application is tightly coupled with other applications and must be aware of their location, protocol, data format, etc., to communicate. This creates significant challenges regarding scalability, reliability, and data consistency. This is where Kafka comes in; it decouples applications, centralizes communication, and ensures efficient, scalable, and reliable data flow.
Kafka, like other messaging systems, simplifies this architecture by providing a centralized, distributed event streaming platform. Applications (producers) can send data to Kafka, and other applications (consumers) can read it without knowing each other’s identities, allowing for decoupled and scalable communications.
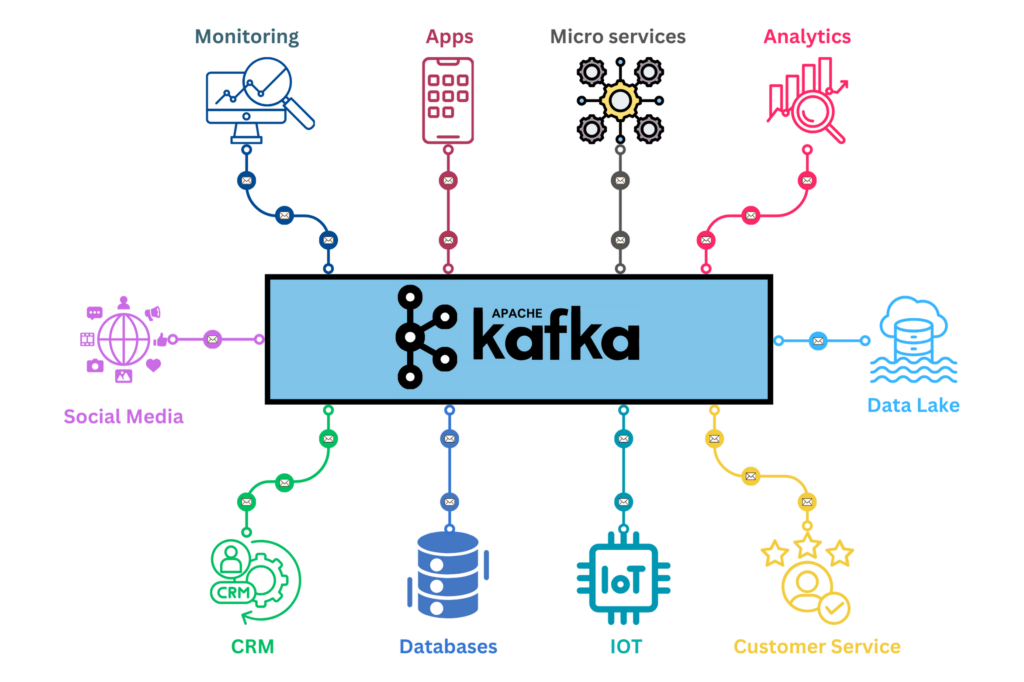
The above is just a sneak peek into Kafka, how it fits into a system, and how it simplifies communication between different applications. In the following sections, we’ll explore how Kafka stands apart from other messaging systems, what makes it so powerful, and how you can leverage it to its maximum potential step by step.
For better navigation, I am splitting the entire discussion into the following topics to make it helpful for anyone looking for specific information.
- Kafka Fundamentals and Internal Architecture: A Deep Dive :- Introduction of Kafka’s fundamental components, such as
messagese, topic, producer, consumer, brokers and ZooKeeper, explain how they work together to provide high availability and fault tolerance. Discuss how messages are stored in partitions, the role of replication in durability, etc. - How Kafka is Fast and Near Real-Time? Digging deep into Its Optimizations :- A deep dive into Kafka’s optimizations, including disk I/O, memory, network, and replication strategies that enable fast, near real-time performance.
- Getting Started with Kafka: A Quick Hands-On Walkthrough :- A quick hands-on walkthrough of starting Kafka, setting up a producer and consumer, and sending messages using the terminal and Java.
- Best Practices for High-Throughput Message Production :- Discuss techniques to optimize
producer performance. Cover configurations likebatch size,linger time,compression types,and how they can be tuned to achieve maximum throughput without compromising data integrity. - Event Sourcing with Kafka: Patterns and Anti-Patterns :- Explore event sourcing an
architectural patternusing Kafka. Discuss its benefits (like auditability), challenges (like complexity), and common pitfalls to avoid when implementing event sourcing in applications. - Overcoming Kafka Scaling Challenges: Lessons from the Real World :- Address the challenges that come with scaling Kafka in large systems. Discuss effective
consumer group management,backpressure scenarios,broker configurationoptimization for high throughput andhorizontal scalingstrategies.
So whether you’re just starting or looking to tackle advanced scenarios, there’s something here for everyone. Without further ado, let’s begin with the first topic.
1. Kafka Fundamentals and Internal Architecture: A Deep Dive
The entire Kafka ecosystem can be divided into different core components. Abstract components, which represent concepts or structures, are called logical components, while tangible components, which are part of the infrastructure and represent actual processes or systems, are called physical components. Below are the different logical and physical components.
Logical components
Physical components
3Producer
4Consumer
5Kafka server (Kafka broker)
6ZooKeeper
At a high level, this is how Kafka operates: Kafka is a distributed system where producers send messages to topics (logical categories for organizing data). Consumers subscribe to specific topics and pull messages from them. ZooKeeper (in older versions) or KRaft (in newer versions) manages metadata such as partition assignments, leader elections, and the overall cluster state, coordinating communication between producers, brokers, and consumers.
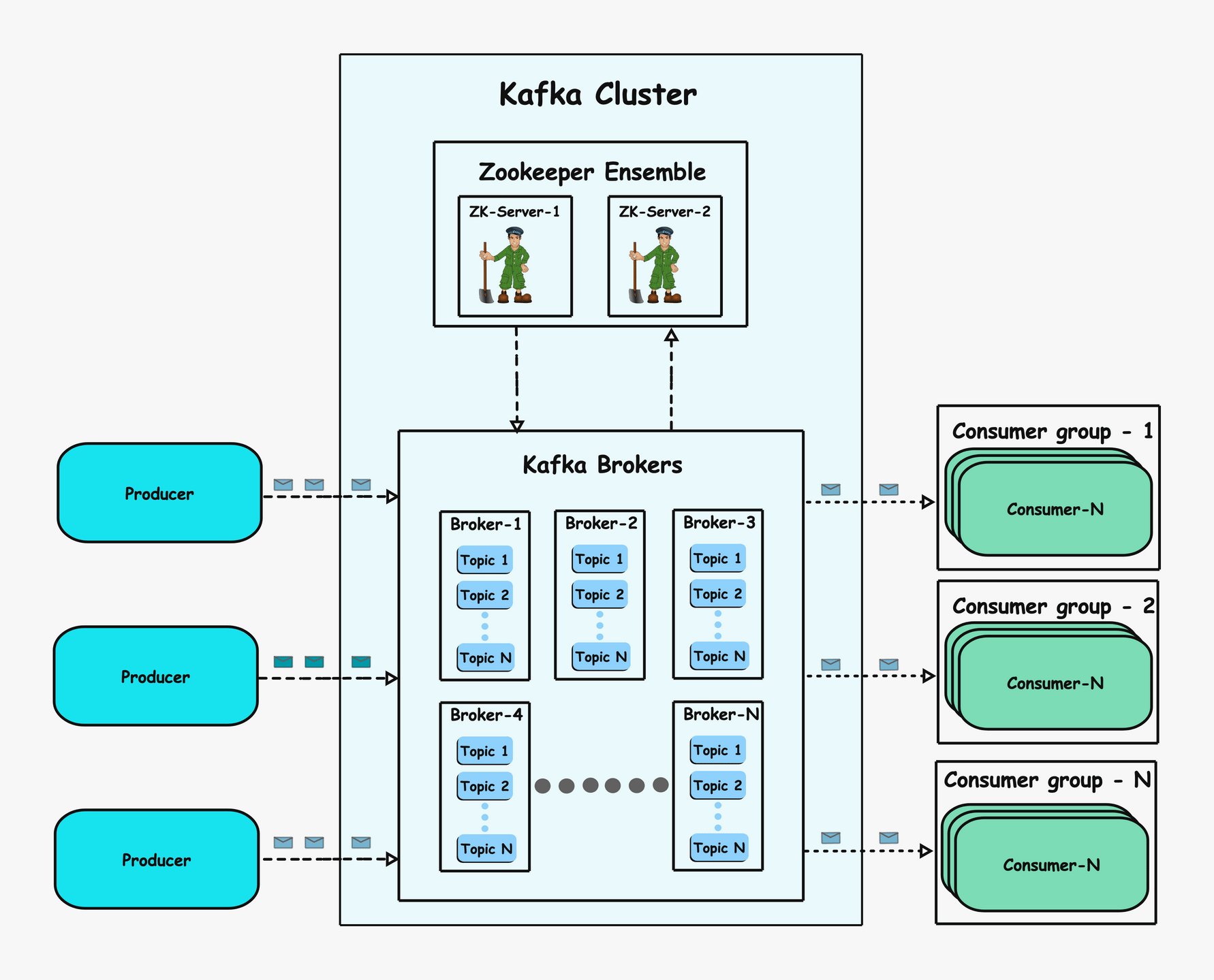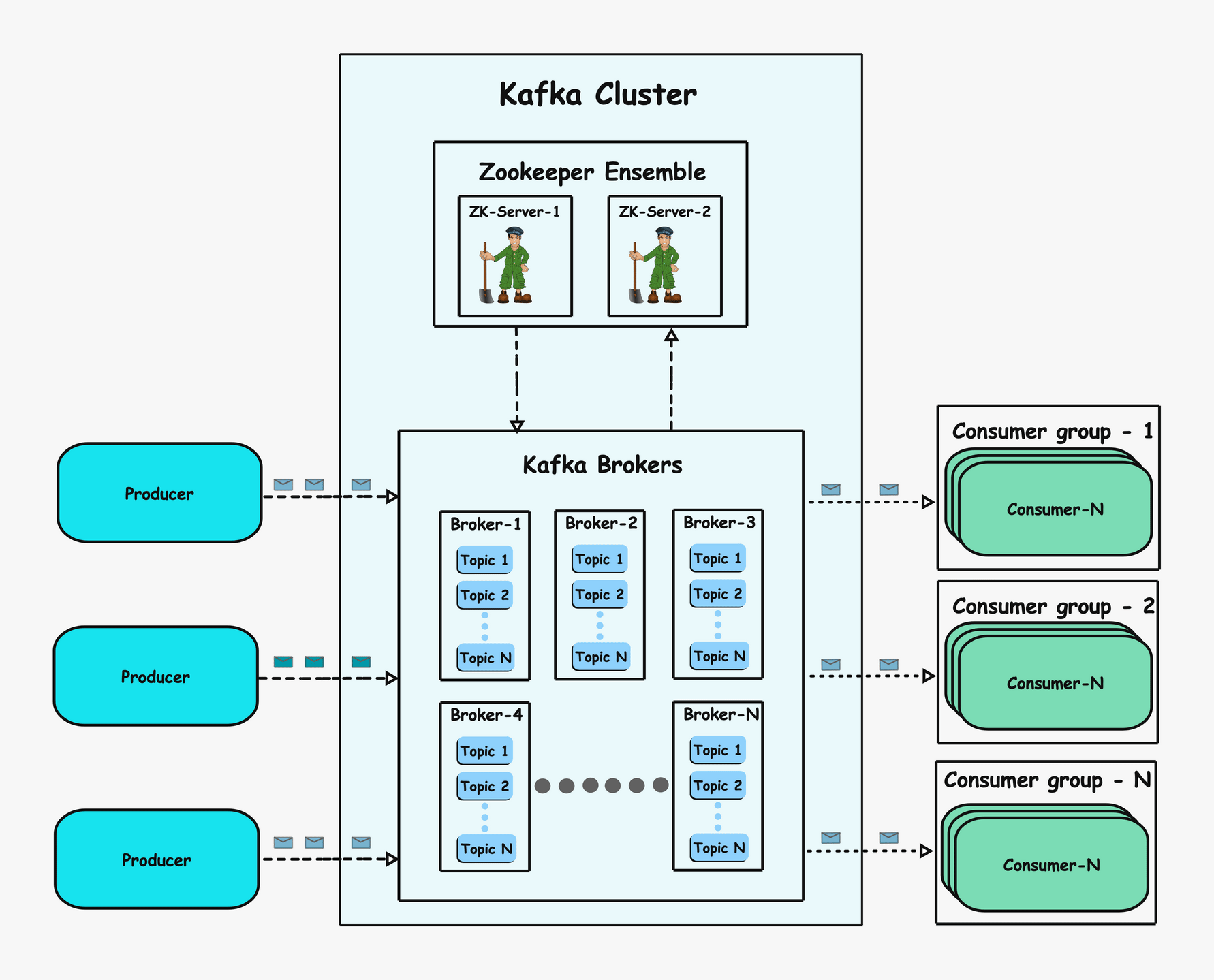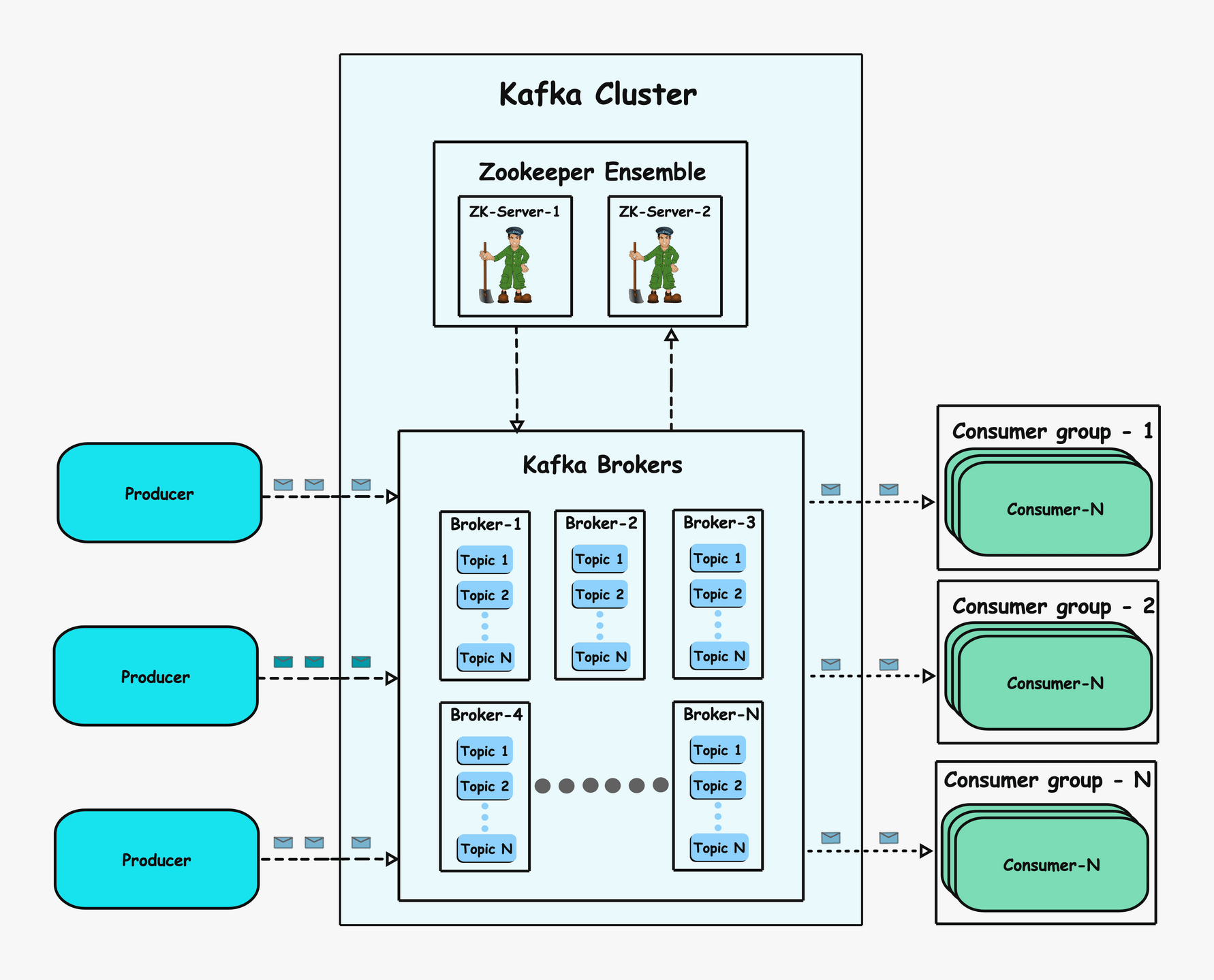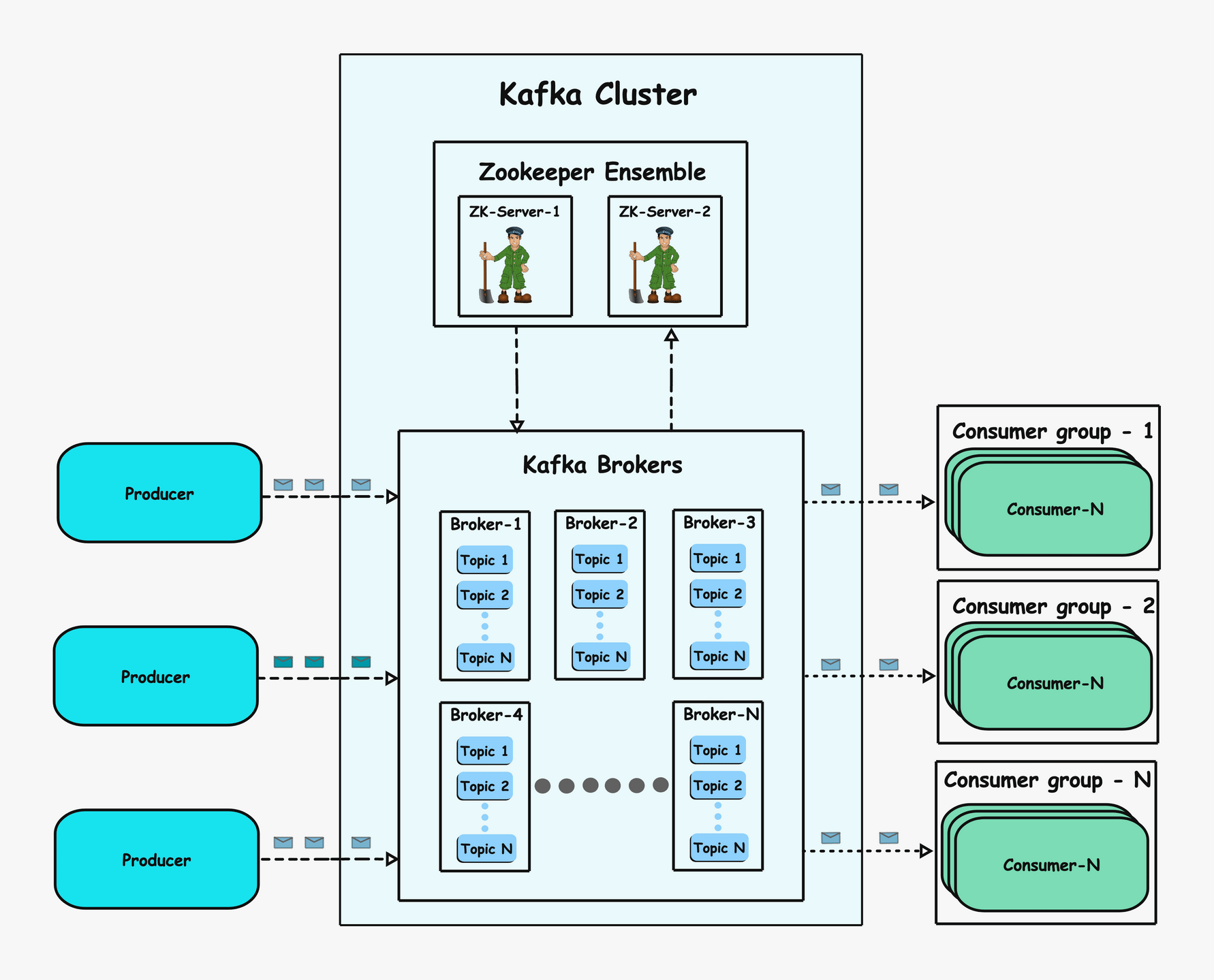
Let’s go over the components in depth.
1Message
A Kafka message is the most basic unit of data sent from the producer to the broker and then consumed by the consumer by pulling it from the broker. Kafka employs a sophisticated system of batching, metadata, and compression to ensure messages are handled efficiently and reliably. Let’s look at the basic part of the message first, then dig deep into the terms batching, metadata, compression, etc.A single message consists of the following key components:
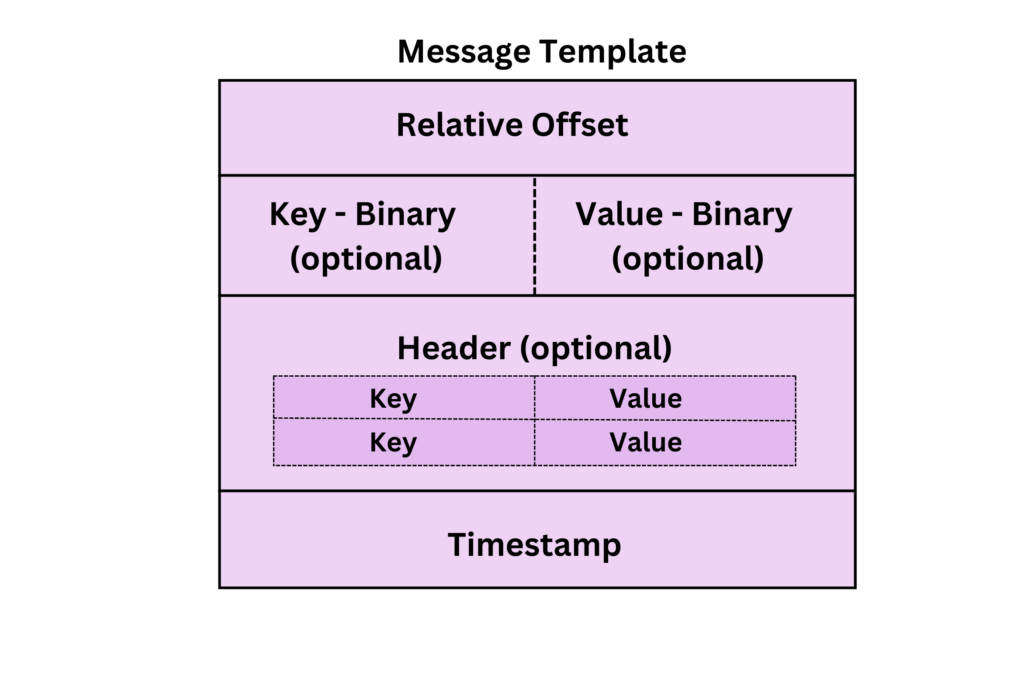
- Relative Offset :- The message’s position in the batch. I will explain the batching shortly. For now, consider it as a sequence number
- Key :- An optional partitioning key determines the partition. If the key is not provided, the producer defaults to round-robin mode, selecting the next partition based on the round-robin algorithm. The key is serialized into a binary format using the serializer class specified in the producer properties under
key.serializer
eg :key.serializer=org.apache.kafka.common.serialization.StringSerializer - Value :- The actual payload, this contain the actual data that a producer wants to publish. The value is serialized into a binary format using the serializer class specified in the producer properties under
value.serializer
eg :value.serializer=org.apache.kafka.common.serialization.JsonSerializer - Headers :- These are optional key-value pairs that provide additional metadata for a message, allowing custom information to be attached without altering the payload.
- Timestamp :- This can be either
CreateTimeorLogAppendTimebased on themessage.timestamp.typeconfiguration at the topic level. If this configuration is set toCreateTimethe producer assigns the timestamp before sending the message to the broker. If the configuration is set toLogAppendTimethe broker is responsible for assigning the timestamp. In this case, the broker generates a single timestamp at the batch level and copies it to each individual message in the batch. More details on batching will be covered shortly.
Kafka always works with bytes, which makes serialization a crucial aspect of its performance. Serialization is the process of converting objects into a byte array so they can be transmitted and stored efficiently. The choice of a serializer directly impacts the speed, size, and compatibility of the data being processed.
Here are some of the most commonly used serializers in Kafka:
- String Serializer :
- Converts strings into a byte array.
- Simple and commonly used for textual data.
- Class: org.apache.kafka.common.serialization.StringSerializer
- Byte Array Serializer :
- Directly sends a pre-constructed byte array.
- Ideal for cases where data is already serialized in a custom format.
- Class: org.apache.kafka.common.serialization.ByteArraySerializer
- Integer Serializer :
- Converts integers into a byte array.
- Efficient for numerical data.
- Class: org.apache.kafka.common.serialization.IntegerSerializer
- Avro Serializer :
- Encodes objects using Avro, a compact and schema-based format.
- Great for compatibility and schema evolution.
- Requires integration with Confluent Schema Registry or similar tools.
- JSON Serializer :
- Converts objects into JSON strings and then to a byte array.
- Human-readable but less compact compared to binary formats like Avro or Protobuf.
- Common for applications needing interoperability.
- Protobuf Serializer :
- Uses Google Protocol Buffers for serialization.
- Compact and efficient for complex objects with schema validation.
- Requires Protobuf libraries and schema definitions.
- Custom Serializer :
- Developers can implement their own serializers by extending Kafka’s Serializer interface.
- Useful for specialized use cases or proprietary formats.
Before moving to the next section, it’s important to discuss one key point about messages in Kafka. Messages are always sent and stored in batches due to the following advantages. Batching is applied only to messages that are sent to the same partition.
- Improves Performance
- Reduces network overhead by sending multiple messages in a single request.
- Allows compression of multiple messages together to save storage and bandwidth.
- Efficient Storage
- Messages are appended to the log in batches, optimizing disk I/O.
Even though Kafka batches messages by default, it allows us to customize the batching behavior by providing the following properties in the producer configuration.
batch.size
- This property defines the maximum size (in bytes) of a batch that the producer will collect before sending it to the broker. The default value is 16384 bytes (16 KB).
- The producer accumulates messages in memory for a specific partition until the total size of the batch reaches the value of batch.size. If the accumulated batch size exceeds this value, the producer sends the batch to the broker immediately, regardless of the linger.ms value.
- Setting this to a very small value ensures only one message fits in a batch, but this can degrade performance, so it should be set carefully.
linger.ms
- This property specifies the maximum time (in milliseconds) the producer will wait before sending a batch of messages to the broker. The default value is 0 ms, which means the producer sends messages immediately without waiting.
- When linger.ms is greater than 0, the producer delays sending a batch to allow more messages to accumulate, which can improve throughput and compression efficiency. If the batch reaches the size specified by batch.size before the linger.ms duration expires, the producer sends the batch immediately.
- Setting linger.ms to a higher value increases batching efficiency but introduces additional latency. For applications requiring low latency, it’s best to keep this value at 0, but for high-throughput scenarios, a small value (e.g., 5-10 ms) can significantly improve performance.
compression.type
- This property specifies the compression algorithm used by the producer to compress batches before sending them to the broker. The default value is none, meaning no compression is applied.
Most popular options include- none – No compression.
- gzip – High compression ratio but higher CPU usage.
- snappy – Optimized for speed with moderate compression.
- lz4 – Balanced compression speed and size.
- zstd – Very high compression ratio with reasonable CPU usage.
Each batch has uncompressed metadata and the compressed version of all the messages.
Kafka batches are stored in a structured format, where the batch metadata and message metadata provide a navigable structure for brokers. Batch-level metadata includes the following info.
- Base Offset: The absolute offset of the first message in the batch.
- Record Count: The number of messages in the batch.
- Producer ID : ID of the producer
- Epoch : Consider as a sequential number act as a transaction id to identify the duplicate messages.
- Compression Type: Specifies how the batch is compressed (e.g., gzip, lz4).
- Batch Size: The total size of the batch.
- Timestamp :- Batch send timestamp
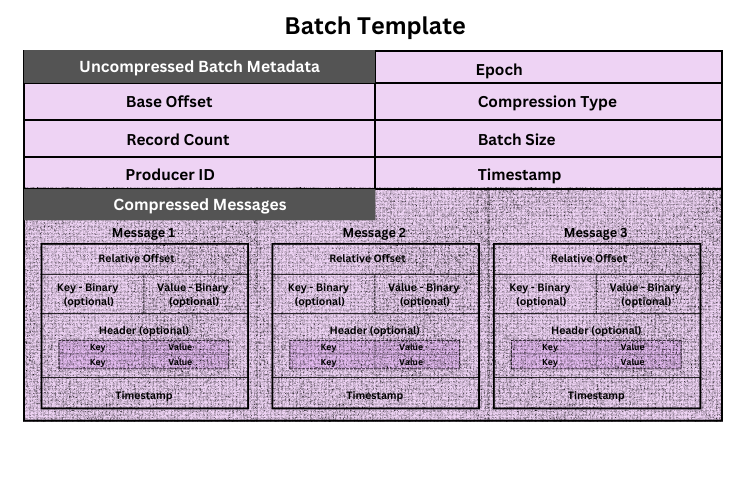
Kafka uses a structured encoding format (like Kafka’s RecordBatch format) that makes it possible for the broker to locate specific fields (like relative offsets) without decompressing the entire payload.
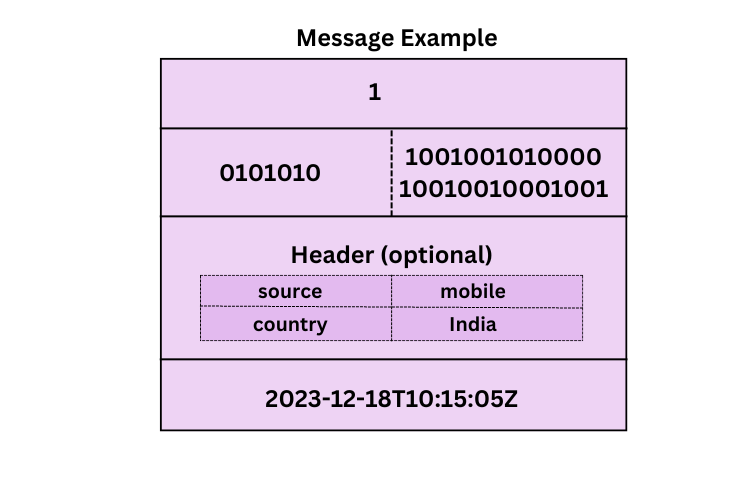
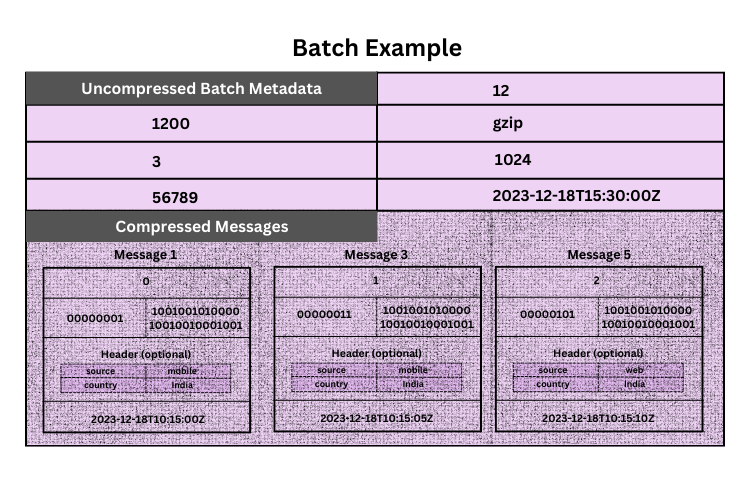
Let’s use an example to explain how the producer batches messages and how they are stored in the broker. Consider a simple system with a topic that has two partitions, and the batch.size is set to 3. Since each message has a key, the producer applies a hash function to the key to determine the partition.
For simplicity, let’s assume the hash function returns Partition 1 for odd numbers and Partition 2 for even numbers. As a result, messages with keys 1, 3, and 5 are assigned to Partition 1. The producer batches these messages (Message 1, Message 3, and Message 5) together before sending them to the broker.
{
"RelativeOffset": 0,
"Key": "user123",
"Value": "Login Event",
"Headers": {
"source": "mobile",
"country":"india"
},
"Timestamp": "2023-12-18T10:15:00Z"
}{
"RelativeOffset": 1,
"Key": "user124",
"Value": "Login Event",
"Headers": {
"source": "mobile",
"country":"india"
},
"Timestamp": "2023-12-18T10:15:05Z"
}{
"RelativeOffset": 2,
"Key": "user125",
"Value": "Login Event",
"Headers": {
"source": "web",
"country":"india"
},
"Timestamp": "2023-12-18T10:15:10Z"
}Then once it is batched the bach message will look like this
{
"BatchMetadata": {
"BaseOffset": 1200,
"RecordCount": 3,
"ProducerID": 56789,
"Epoch": 12,
"CompressionType": "gzip",
"BatchSize": 512,
"MaxTimestamp": "2023-12-18T10:15:10Z"
},
"Messages": [
{
"RelativeOffset": 0,
"Key": "user123",
"Value": "Login Event",
"Headers": {
"source": "mobile",
"country": "india"
},
"Timestamp": "2023-12-18T10:15:00Z"
},
{
"RelativeOffset": 1,
"Key": "user124",
"Value": "Login Event",
"Headers": {
"source": "mobile",
"country": "india"
},
"Timestamp": "2023-12-18T10:15:05Z"
},
{
"RelativeOffset": 2,
"Key": "user125",
"Value": "Login Event",
"Headers": {
"source": "web",
"country": "india"
},
"Timestamp": "2023-12-18T10:15:10Z"
}
]
}
In this setup, the messages field is compressed, while the metadata remains uncompressed. When the broker receives the batch, it assigns the base offset and, if configured, may update the timestamp as well. These operations are performed without decompressing the data, relying on the structured format of the batch for efficient parsing.
The broker saves data in batches in the log file and maintains an index in the index file. In the index file, each message is assigned its own offset, which maps to the byte offset in the log file where the message starts.
For example, if the base index starts at 1200, the index table calculates each message’s offset by adding the base index to the relative offset within the batch. Thus:
- Message 1 will have an offset of 1200.
- Message 3 will have an offset of 1201.
- Message 5 will have an offset of 1202.
Each offset in the index file points to the specific byte position in the log file where the message is stored. Using this byte position, the broker can identify the corresponding batch.
---------------------------------------------------------
| Relative Offset | Position in Log File (bytes) |
---------------------------------------------------------
| 1200 | Offset 250 (Start of Message 1) |
| 1201 | Offset 450 (Start of Message 3) |
| 1202 | Offset 612 (Start of Message 5) |
---------------------------------------------------------
---------------------------------------------------------
| Base Offset | Last Offset | Record Count | Size (bytes) |
---------------------------------------------------------
| 100 | 102 | 3 | 512 |
---------------------------------------------------------
| Compression Type: gzip |
---------------------------------------------------------
| Messages: |
---------------------------------------------------------
| Offset: 100 | Key: user123 | Value: Login Event |
| Headers: | source: mobile, country: india |
| Timestamp: 2023-12-18T10:15:00Z |
| Size: 200 |
| Position in Log File: Offset 250 |
---------------------------------------------------------
| Offset: 101 | Key: user124 | Value: Login Event |
| Headers: | source: mobile, country: india |
| Timestamp: 2023-12-18T10:15:05Z |
| Size: 150 |
| Position in Log File: Offset 450 |
---------------------------------------------------------
| Offset: 102 | Key: user125 | Value: Login Event |
| Headers: | source: web, country: india |
| Timestamp: 2023-12-18T10:15:10Z |
| Size: 162 |
| Position in Log File: Offset 612 |
---------------------------------------------------------
When a consumer requests a specific offset, the broker searches the index file for that offset, identifies the byte position in the log file, and retrieves the entire batch containing that offset. It is then the consumer’s responsibility to filter the specific message by offset from the batch.
Typically, instead of requesting specific offsets, consumers use the poll() method to fetch messages from the broker, retrieving entire batches starting from the current offset. This batch-based approach is efficient as it minimizes network overhead and allows consumers to process messages sequentially in bulk. While consumers can explicitly seek specific offsets if needed, the default behavior is to process entire batches, aligning with Kafka’s design for high-throughput streaming.
This is enough for now regarding messages. I have simplified the explanation for better understanding, but there can be additional metadata in a message, such as Checksum, Timestamp Type, Transaction Metadata, and more.
2Topic
In simpler terms, a topic is a logical categorization of messages in Kafka. When a producer sends a message, it does so to a specific topic that act like a named destinations for messages. For example, in an e-commerce system, an order creation event might send messages to a topic named order_creation. Similarly, a review created event could send messages to a topic named review_created.
In some cases, multiple events can send messages to the same topic. For instance, a send_mail topic could be used for events triggered during order creation, dispatch, or returns, as they all involve sending emails.
Kafka topics let producers and consumers work independently by communicating through the topic instead of directly with each other. This makes the system flexible, allowing producers and consumers to change without affecting one another.
Multiple producers can send messages to the same topic, and multiple consumers can read from it at the same time, making it scalable and efficient. Kafka also ensures messages are saved using retention rules like keeping them for a set time (e.g., 7 days), until the log reaches a certain size, or only keeping the latest message for each key (compaction).
Each topic is divided into different partitions, and messages are distributed to these partitions based on the hash of the message key. If no key is provided, messages are distributed in a round-robin fashion.
These partitions are replicated and distributed across multiple brokers, ensuring fault tolerance and high availability. If a broker fails, Kafka automatically uses the replicas from other brokers to continue serving the data without interruption. This design also enables parallel processing, as each partition can be processed independently by different consumers in a consumer group.
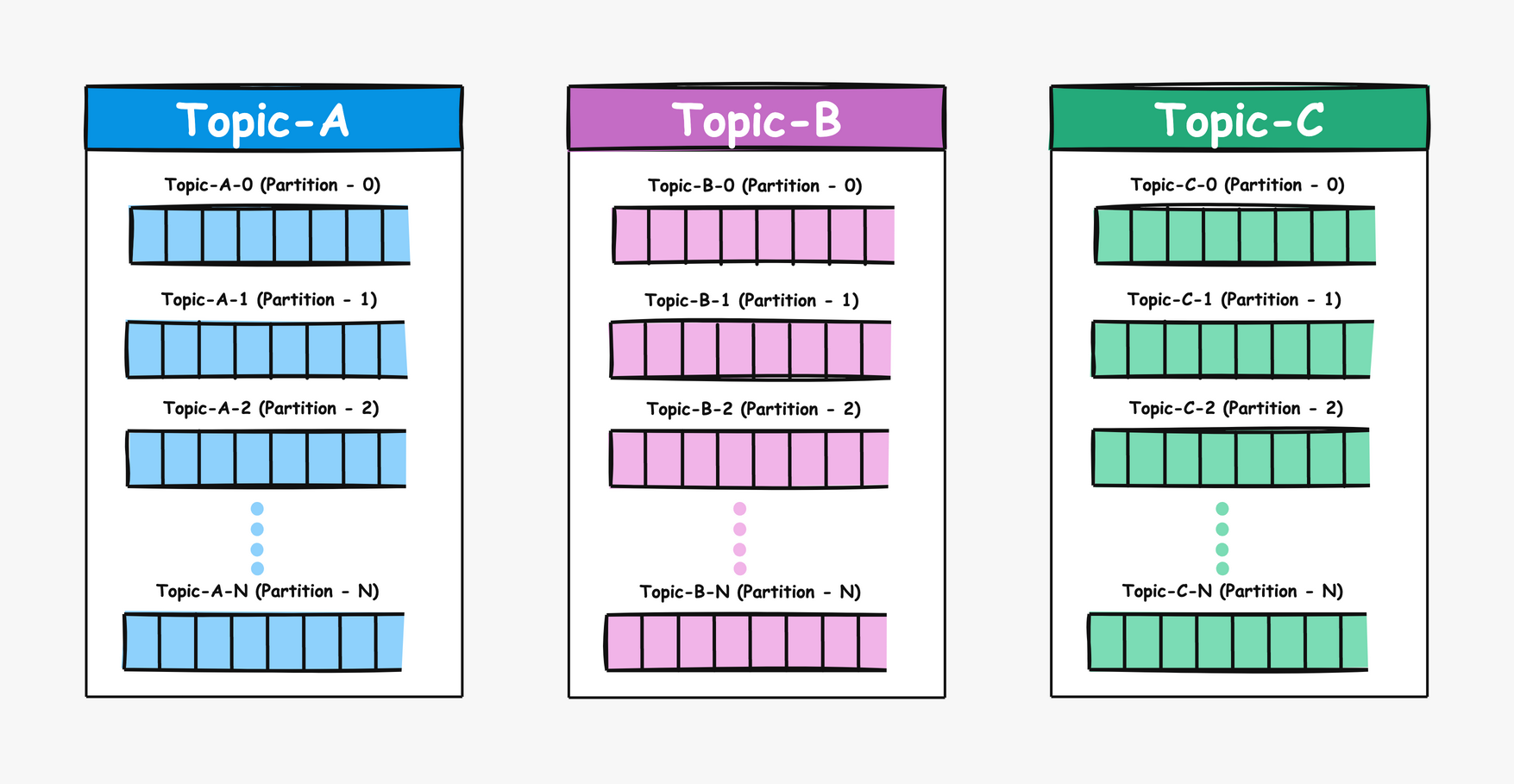
Messages within a partition are ordered by their offsets, ensuring that consumers receive them in the same order they were produced. However, Kafka does not guarantee ordering across partitions, as each partition operates independently. For each partition, one broker acts as the leader, while other brokers serve as followers.
The leader is responsible for handling all read and write operations, while the followers replicate the leader’s data to ensure fault tolerance. If the leader broker fails, one of the followers is automatically elected as the new leader to maintain availability.
Kafka uses the Murmur2 algorithm to determine the target partition for a message. The formula used for calculating the partition is as follows
targetPartition = Math.abs(Utils.murmur2(keyBytes)) % numberOfPartitions
Let’s look at an example to understand how partitioning works. Assume we are producing messages to a topic called order_created, which has three partitions. We have 9 messages, each with an integer order ID as the key.
For simplicity, we won’t use the Murmur2 algorithm here. Instead, we’ll use the key directly as it is an integer value. The formula for determining the partition in this example is:
targetPartition = integerKey % numberOfPartitionsUsing the above formula the following is the partition calculation for each message
| Key | Formula | Partition |
|---|---|---|
| 1 | 1%3 | 1 |
| 2 | 2%3 | 2 |
| 3 | 3%3 | 0 |
| 4 | 4%3 | 1 |
| 5 | 5%3 | 2 |
| 6 | 6%3 | 0 |
| 7 | 7%3 | 1 |
| 8 | 8%3 | 2 |
| 9 | 9%3 | 0 |
In this example, you can see that messages with keys 3, 6, and 9 are assigned to Partition 0; keys 1, 4, and 7 go to Partition 1; and keys 2, 5, and 8 are assigned to Partition 2.

The above image illustrates Kafka’s physical storage structure in the filesystem. Kafka uses detailed naming conventions to organize data, where each topic-partition is represented by a distinct set of files.
The Kafka data directory, configured via the log.dirs property, is typically located at /var/lib/kafka/data. Each topic has its own folder within this directory, and the files for individual partitions are named based on the topic name and partition number. For example, for a topic named order_created with 3 partitions, the folder path would be /var/lib/kafka/data/order_created_<partition-number>, containing files for each partition.
Each partition folder primarily contains three types of files
- Log Files: Store the actual message data.
- Index Files: Map offsets to physical positions in the log files.
- Time Index Files: Map timestamps to physical positions in the log files.
/var/lib/kafka/data/
order_created-0/ # Partition 0 of the topic 'order_created'
00000000000000000000.log # Log file for Partition 0 base offset 0
00000000000000000000.index # Offset index for Partition 0 base offset 0
00000000000000000000.timeindex # Time index for Partition 0 base offset 0
00000000000000000010.log # Log file for Partition 0 base offset 10
00000000000000000010.index # Offset index for Partition 0 base offset 10
00000000000000000010.timeindex # Time index for Partition base offset 10
order_created-1/ # Partition 1 of the topic 'order_created'
00000000000000000000.log # Log file for Partition 1
00000000000000000000.index # Offset index for Partition 1
00000000000000000000.timeindex # Time index for Partition 1
order_created-2/ # Partition 2 of the topic 'order_created'
00000000000000000000.log # Log file for Partition 2
00000000000000000000.index # Offset index for Partition 2
00000000000000000000.timeindex # Time index for Partition 2
Within a partition folder, multiple log files are created, with each file representing a log segment. The creation of new log segments is controlled by
- Segment Size: Managed by
log.segment.bytes(default: 1 GB or 1073741824 bytes). - Time-Based Rolling: Controlled by
log.roll.msorlog.roll.hours(default: 7 days or 604800000 ms).
The total number of log files for a partition is further influenced by retention policies, which determine how long or how much data to retain
- Time-Based Retention: Configured via
log.retention.hoursorlog.retention.ms. - Size-Based Retention: Configured via
log.retention.bytes, limiting the total size of all log files in the partition.
Following is an example how these configuration look like in broker configuration file
# Kafka Data Directory
log.dirs=/var/lib/kafka/data1, /var/lib/kafka/data2 # Path where Kafka stores topic-partition data, kafka will distribute the partition among data1 and data2
# Segment Size Configuration
log.segment.bytes=536870912 # Set maximum size of a log segment (512 MB)
# Time-Based Rolling Configuration
log.roll.ms=43200000 # Roll logs every 12 hours (in milliseconds)
# Alternatively:
# log.roll.hours=12 # Roll logs every 12 hours (in hours)
# Time-Based Retention Configuration
log.retention.ms=259200000 # Retain logs for 3 days (in milliseconds)
# Alternatively:
# log.retention.hours=72 # Retain logs for 72 hours (in hours)
# Size-Based Retention Configuration
log.retention.bytes=10737418240 # Retain up to 10 GB of logs per partition3Producer
In previous sections, we have already discussed producers extensively, including topics such as sending messages in batches, determining partitions, data key and value serialization, and compression. In this section, we will cover some additional aspects that the producer handles.
As we know, the producer is responsible for pushing data to a Kafka topic. It plays a crucial role in ensuring that data reliably reaches the correct topic and partition while managing retries, acknowledgments, and error handling. The producer’s primary tasks include serializing the data, sending it to the appropriate broker, and handling any responses from the broker.
Key Producer Responsibilities
- Broker Communication:
- After determining the target partition, the producer sends the message batch to the leader broker of that partition.
- The leader broker handles both writes and acknowledgment for the batch.
Note:- More about the leader broker and follower broker will be explained in the broker section
- Acknowledgment (acks Configuration):
- The producer waits for an acknowledgment from the broker, based on the acks setting in the producer config file:
- acks=0: No acknowledgment is expected. Fastest but unreliable.
- acks=1: Acknowledgment is sent when the leader writes the batch to disk.
- acks=all: All in-sync replicas (ISR) must confirm receipt before acknowledgment.
- This ack setting is communicated to the broker as part of the produce request header.
Note:- More about in-sync replicas (ISR) will be explained in the broker section
- The producer waits for an acknowledgment from the broker, based on the acks setting in the producer config file:
- Retries and Idempotence:
- If a message send fails (due to leader failure, network issues, etc.), the producer can retry sending the batch.
- Retries (retries): Number of retry attempts if the batch fails. Following are the different conditions the producer retries
- REQUEST_TIMEOUT :- No acknowledgment from broker within request.timeout.ms. In this case, the producer will retry to send the batch.
- LEADER_NOT_AVAILABLE :- Leader broker is unavailable (leader failover). In this case, the producer will wait for a new leader and retry.
- NETWORK_EXCEPTION :- Connection issues or broker unreachable. In this case, the producer will retry after connection reset.
- NOT_ENOUGH_REPLICAS :- Not enough ISR replicas for acks=all. In this case, the producer will retry unit ISR stabilizes.
- THROTTLING_QUOTA_EXCEEDED :- Quotas exceeded (producer throttled). In this case, the producer will wait for throttle time to expire and retry.
- Idempotent Producer (enable.idempotence=true): Ensures no duplicate messages, even if retries are needed.
Note : More about this will be discussed later.
- Error Handling:
- The producer can be configured to handle specific failures, such as:
- Time-out errors: When a message batch takes too long to be acknowledged. There are two different
- Serialization failures: When the key or value cannot be serialized properly.
- The producer can be configured to handle specific failures, such as:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("retries", "5");
props.put("enable.idempotence", "true");
props.put("acks", "all"); Here is a cookbook of producer properties. Not all of them are explained here, as it would be too much to absorb and beyond the scope of this blog. Some have already been discussed, while others will be covered in later sections.
# --------------------------------------------
# Producer Connection Configuration
# --------------------------------------------
bootstrap.servers=localhost:9092 # Comma-separated list of broker addresses (default: none)
client.id= # Optional identifier for the producer client (default: "")
# --------------------------------------------
# Serialization Configuration
# --------------------------------------------
key.serializer=org.apache.kafka.common.serialization.StringSerializer # Serializer for keys (default: none)
value.serializer=org.apache.kafka.common.serialization.StringSerializer # Serializer for values (default: none)
# --------------------------------------------
# Acknowledgment Configuration
# --------------------------------------------
acks=1 # Controls the acknowledgment behavior (default: 1)
# 0: No acknowledgment, 1: Leader acknowledgment, all: All ISR replicas acknowledge
# --------------------------------------------
# Retry Configuration
# --------------------------------------------
retries=2147483647 # Number of retry attempts (default: 2147483647 - practically infinite retries)
retry.backoff.ms=100 # Time to wait between retry attempts (default: 100ms)
enable.idempotence=false # Ensures no duplicate messages during retries (default: false)
# --------------------------------------------
# Timeouts and Blocking
# --------------------------------------------
request.timeout.ms=30000 # Time to wait for acknowledgment from broker (default: 30000ms / 30 seconds)
delivery.timeout.ms=120000 # Maximum time allowed for delivery attempts, including retries (default: 120000ms / 2 minutes)
max.block.ms=60000 # Maximum time the producer will block when the send buffer is full (default: 60000ms / 1 minute)
# --------------------------------------------
# Batching and Buffering
# --------------------------------------------
batch.size=16384 # Maximum batch size in bytes (default: 16384 bytes / 16KB)
linger.ms=0 # Time to wait before sending a batch, even if the batch size is not reached (default: 0ms)
buffer.memory=33554432 # Total memory size allocated for buffering records (default: 33554432 bytes / 32MB)
# --------------------------------------------
# In-Flight Requests and Ordering
# --------------------------------------------
max.in.flight.requests.per.connection=5 # Maximum number of unacknowledged requests per broker connection (default: 5)
# --------------------------------------------
# Compression
# --------------------------------------------
compression.type=none # Type of compression for batches (default: none)
# Options: none, gzip, snappy, lz4, zstd
# --------------------------------------------
# Partitioner Configuration
# --------------------------------------------
partitioner.class=org.apache.kafka.clients.producer.internals.DefaultPartitioner # Default partitioner (uses key hash or round-robin)
interceptor.classes= # List of classes for producer interceptors (default: empty)
# --------------------------------------------
# Transactional Configuration
# --------------------------------------------
transactional.id= # Unique ID for transactional producers (default: null)
transaction.timeout.ms=60000 # Timeout for a transaction before being aborted (default: 60000ms / 1 minute)
# --------------------------------------------
# Security Configuration (for TLS and SASL)
# --------------------------------------------
security.protocol=PLAINTEXT # Security protocol (default: PLAINTEXT)
ssl.keystore.location= # Path to the keystore (for SSL)
ssl.keystore.password= # Password for the keystore
sasl.mechanism= # SASL mechanism (default: "")
sasl.jaas.config= # JAAS configuration for SASL authentication
# --------------------------------------------
# Miscellaneous
# --------------------------------------------
send.buffer.bytes=131072 # Size of the TCP send buffer (default: 131072 bytes / 128KB)
receive.buffer.bytes=32768 # Size of the TCP receive buffer (default: 32768 bytes / 32KB)
metadata.max.age.ms=300000 # Maximum age of the metadata before a refresh is forced (default: 300000ms / 5 minutes)
connections.max.idle.ms=540000 # Maximum idle time for a connection before closing it (default: 540000ms / 9 minutes)
4Consumer
By now, you might have a fair idea of what a consumer is, right? yes, it is a client application that reads messages from Kafka topics. Kafka consumers are designed to pull messages from brokers rather than having messages pushed to them, providing more control over message processing.
Why polling / pull rather than pushing
First of all, this is a careful design choice by Kafka compared to other push-based pub-sub models like ActiveMQ and RabbitMQ. A push-based system becomes very complex as the system scales. For example, a push-based system needs to ensure that consumers are alive; for that, consumers must send frequent heartbeats to the broker or server. This creates an extra network call that the consumer must make in addition to receiving normal push messages from the server. The frequency of these calls is typically quite high, as any heartbeat mechanism requires short intervals to notify the broker of the consumer’s availability.
In contrast, with a pull mechanism, the consumer retrieves messages from the broker at regular intervals defined by its consumption capacity, rather than relying on a frequent timer to indicate liveliness. This approach reduces overall network calls since the same poll request serves both as a heartbeat and for data fetching.
Following are some of the benefits of polling.
- Consumer Control Over Data Rate:
- With polling, consumers control how many messages they fetch and when to fetch them.
- This helps consumers manage their own processing speed and avoid being overwhelmed by too many messages.
- Efficient Batching:
- Polling allows consumers to fetch messages in batches (max.poll.records), which reduces the overhead of frequent network requests and improves throughput.
- Backpressure Handling:
- Since consumers request data based on their readiness, there is no risk of buffer overflow at the consumer side due to unprocessed messages.
- In a push-based system, if a consumer cannot process messages fast enough, the incoming messages can overwhelm its buffer, leading to crashes.
- Avoiding Consumer Overload:
- In use cases where consumers have varying workloads, polling enables consumers to fetch data at their own pace.
- Rebalancing and Partition Assignment:
- When a consumer leaves or joins the group, rebalancing occurs, and polling helps the consumer detect when it needs to reassign partitions.
- In a push-based model, partition rebalancing and message ordering become harder to maintain.
Note:- More on this in the later sections
Long poll
As we mentioned earlier, the polling mechanism on the consumer side is not a typical polling process where the consumer continuously polls. Instead, it is a well-calculated long polling mechanism in which the consumer accepts a timeout that defines how long it will wait if no messages are available. If the timeout value is set to a longer duration, the consumer performs a long poll, meaning it will wait for data up to the specified time before returning an empty batch.
consumer.poll(Duration.ofMillis(1000)); // The consumer will wait for 1 second before returning.Following are some of the additional properties that contribute to the dynamics of long polling.
# --------------------------------------------
# Long Polling and Batching Configuration
# --------------------------------------------
# Time (in milliseconds) the broker waits before sending data, even if the minimum batch size (fetch.min.bytes) is not reached.
# Default: 500 ms
# Recommended: 1000 ms or higher for large batches.
fetch.max.wait.ms=1000 # Waits up to 1 second before sending data
# Minimum amount of data (in bytes) the broker should wait to accumulate before sending a batch of messages to the consumer.
# Default: 1 byte
# Recommended: 1 MB (1048576 bytes) or higher for batch processing to improve throughput.
fetch.min.bytes=1048576 # 1 MB minimum data fetch size
# Maximum number of records the consumer will return in a single poll.
# Default: 500
# Recommended: 500 to 1000 records for high throughput, depending on memory.
max.poll.records=1000 # Limit the number of messages per poll to avoid consumer overload
Offset Management and Commit Strategies
In Kafka, offset management plays a crucial role in ensuring that consumers can keep track of their progress while reading messages from partitions. Offsets indicate the position of the last message a consumer has processed, and commit strategies determine when and how these offsets are stored for recovery purposes.
Following are some of the important aspects of offset and commit strategies:
- Consumers keep track of their progress using an in-memory offset variable to determine the last consumed message. This offset includes the details of
- Topic Name – The name of the topic being consumed.
- Partition – The partition number assigned to the consumer.
- Next offset – The next offset to be fetched by the consumer during polling.
- Last processed offset – The offset of the last successfully processed message.
- Last committed offset – The last offset that was committed to the broker.
- Consumers commit the last processed offset to a dedicated topic called
__consumer_offsets. Even though it’s a regular topic internally, it is managed specially by Kafka due to its critical role. Each offset is saved as a key-value pair and it includes the details to identify a consumer group and its consumption status.- Key :- unlike other keys in kafka message this includes
- Consumer group ID (e.g., order-processing-group)
- Topic name (e.g., order_events)
- Partition number (e.g., partition 0)
- Value
- The committed offset
- Metadata (like debug tags, if any)
- Timestamp
- Key :- unlike other keys in kafka message this includes
- Offset Fetch :- When the consumer joins or rejoins, it sends an OffsetFetchRequest to the broker to fetch the last committed offsets for the assigned partitions from the __consumer_offsets topic. If there is no offset available for a consumer group’s partition, then Kafka must determine where to start reading messages from the topic partitions. In such cases, Kafka follows the configuration provided in the
auto.offset.reset property. The possible values are as follows:- earliest – Start reading messages from the beginning of the partition (offset 0).
- latest – Start reading messages from the end of the partition (only new messages).
- none – Throw an exception if no offset is found for the partition.
- __consumer_offsets is partitioned into 50 partitions by default to distribute the load. The key-value pairs are hashed to determine the partition and indexed by offset within each partition to facilitate faster lookups. A typical example of offset fetching would look like
- key construction (group.id + topic + partition)
eg: Key = “order-processing-group|order_events|0” - Hashing :- To find the partition
eg: Hash(“order-processing-group|order_events|0”) → Partition 37 - Indexing :- In each partition, the entries are indexed based on offset. This offset-based index is not directly helpful when searching for the last committed offset for a specific consumer group, topic, and partition, as the broker does not know the exact offset at that time. However, the offset index becomes helpful when the
auto.offset.resetproperty is set to earliest or latest.
eg: Offset 1500 → Byte Position 384 KB - Sequential Scan :- Scans the log for the exact key-value pair. If it is searching for the last committed offset, the scan proceeds bottom-up, as the first matching entry from the bottom represents the latest offset for that particular key-value pair.
- key construction (group.id + topic + partition)
Kafka Consumer group Lifecycle
In this section we will cover In Kafka, consumers are part of consumer groups and perform various activities such as joining, rebalancing, and rejoining based on events like new consumers joining, existing consumers leaving, or crashes. Additionally, we will cover topics such as consumer offset commits, partition assignments, and related processes.
1. Consumer Group
A consumer group is a collection of one or more consumers that work together to consume messages from a set of partitions in a Kafka topic.

Following are some of the important aspects of the consumer group
- Partition Assignment :- Eeach partition of a topic is consumed by only one consumer within the group, enabling parallelism while ensuring no message duplication within the group.
eg:- In the above image, the partition-1 of topic-A is assigned to only consumer-1 in the consumer group 1. - Sequential Partition Read :- One consumer can consume messages from different partitions of the same topic, but the processing is sequential, not parallel.
eg:- Consumer-1 of consumer group 2 is consuming partition-1 and partition-2 of topic-A - Sequential Topic Reads :- One consumer can consume messages from different partitions of the different topics, even here the processing is sequential, not parallel.
eg:- Consumer-1 of consumer group 1 is consuming partition-1 of both topic-A and topic-B - Parallel Processing :- Multiple consumers in a group can process data from different partitions in parallel.
eg:- consumer-1 and consumer-2 from consumer group 1 are consuming messages from partition-1 and partition-2 of topic-A in parallel. - Consumer Limit :- The total number of consumers in a group cannot exceed the total number of partitions. If there are more consumers than partitions, the extra consumers will remain idle.
eg:- consumer-2 from consumer group 1 is not consuming any messages from topic-B as it has only two partitions, and those are consumed by consumer-1 and consumer-3.
2. Consumer joining, leaving, rebalancing, and rejoining
The following are the step-by-step processes involved when a consumer joins or rejoins a Kafka consumer group. When a consumer leaves, a similar process occurs for the remaining consumers, but they can skip the first two steps since they are already part of the consumer group.
- Identification of Group Coordinator :- Each consumer instance identifies the group coordinator for its consumer group. The group coordinator is responsible for managing the membership and partition assignments within the group.
- JoinGroupRequest :- The consumer sends a JoinGroupRequest to the group coordinator broker, providing the consumer group ID and the list of subscribed topics.
- Rebalance Trigger :- The group coordinator triggers a rebalance to redistribute partitions among all active consumers in the group. This ensures that every partition of the topic is assigned to one consumer.
Note:- More about the rebalance will be covered shortly. - Partition Assignment :- The group leader (one of the consumers selected by the coordinator) assigns partitions to each consumer according to the configured partition assignment strategy (e.g., Range, RoundRobin, or Sticky).
Note:- More about the partition strategy will be covered shortly. - SyncGroupRequest :- After receiving the partition assignments, the consumers send a SyncGroupRequest to confirm their readiness to start consuming messages from the assigned partitions.
- Acknowledgment :- The group coordinator sends back a SyncResponse to each consumer, notifying them of their respective partition assignments.
- Offset Fetch :- The consumer sends an OffsetFetchRequest to the broker to fetch the last committed offsets for the assigned partitions from the __consumer_offsets topic.
- Start Polling :- After fetching the offsets, the consumer starts calling poll() to request batches of messages from the assigned partitions.
3. Rebalancing and Partition assignment
As you know, rebalancing is moving or redistributing partitions among the available consumers. Before moving forward, let’s discuss two important stakeholders in rebalancing and partition assignment.
- Group Leader: The group leader is the first consumer to join a consumer group. It is responsible for managing partition assignments among the consumers in that group. The leader receives a list of all active consumers from the group coordinator and assigns partitions to each consumer based on this information. The leader uses an implementation of the
PartitionAssignorinterface to determine which partitions should be handled by which consumer. - Group coordinator: The group coordinator is a broker that oversees the consumer group. It manages the membership of consumers in the group and monitors their health and liveliness. If a consumer fails to signal that it is alive within a specified timeout, the coordinator triggers a rebalance of the partitions among the remaining consumers
Let’s look at the situations where Kafka performs rebalancing.
- New Consumer Joins the Group:
- When a new consumer joins the group, the group coordinator redistributes partitions to ensure an even load among consumers.
- Existing Consumer Leaves the Group:
- If a consumer leaves (due to a crash, shutdown, or network issue), the remaining consumers must take over the partitions assigned to the departed consumer.
- Partition Reassignment (Broker/Topic Changes):
- If new partitions are added to a topic or a broker fails and recovers, Kafka reassigns partitions among consumers.
- Subscription Changes:
- If a consumer changes its subscribed topics, a rebalance is triggered to reflect the new subscriptions.
There are two different types of rebalance
Eager Rebalance (Traditional Approach) This is also known as Stop The World rebalancing as in this all consumers in the group stop processing messages and release their partitions whenever a rebalance is triggered. The group then undergoes a complete redistribution of all partitions.

This is the traditional rebalance protocol in Kafka and is used by the default partition assignment strategies such as
- RangeAssignor (Default): Assigns contiguous ranges of partitions to each consumer.
- Example: For 10 partitions and 3 consumers:
- Consumer 1: Partitions 0, 1, 2, 3
- Consumer 2: Partitions 4, 5, 6
- Consumer 3: Partitions 7, 8, 9
- Example: For 10 partitions and 3 consumers:
- RoundRobinAssignor: Distributes partitions evenly in a round-robin manner across consumers.
- Example: For 10 partitions and 3 consumers:
- Consumer 1: Partitions 0, 3, 6, 9
- Consumer 2: Partitions 1, 4, 7
- Consumer 3: Partitions 2, 5, 8
- Example: For 10 partitions and 3 consumers:
- StickyAssignor: Attempts to maintain the same partition assignments during rebalancing to avoid unnecessary partition movement.
- Example: If Consumer 3 leaves, the partitions assigned to Consumer 3 are reassigned with minimal changes to other consumers’ assignments.
- Example: If Consumer 3 leaves, the partitions assigned to Consumer 3 are reassigned with minimal changes to other consumers’ assignments.
Cooperative Rebalance (Incremental Approach)It is an incremental rebalance protocol designed to minimize the disruption caused by rebalancing in Kafka consumer groups. Unlike eager rebalance, where all consumers in the group revoke their partitions and stop processing messages, cooperative rebalance only reassigns the necessary partitions, allowing unaffected consumers to continue processing

It uses partition assignment strategies such as
- CooperativeStickyAssignor (Default for Cooperative Rebalance): It is designed to keep partitions “sticky“, meaning it tries to retain the same partition assignments for consumers during rebalancing.
- IncrementalCooperativeAssignor (Future Strategy): This assignor builds upon CooperativeStickyAssignor but adds more optimizations for dynamic topic subscriptions and topic migrations. Although not widely used or enabled by default, Kafka’s roadmap includes incremental cooperative assignors that further reduce partition reassignment complexity.
4. Acknowledgment and Delivery Guarantees
Kafka provides three different delivery guarantees to ensure that messages are consumed and processed correctly. These guarantees depend on the consumer’s acknowledgment (commit) behavior and how offsets are managed.
1. At-Least-Once Delivery Guarantee
In this the consumer commits the offset only after processing the message. This approach ensures that no messages are lost, although duplicates may occur.
If the consumer fails after processing a message but before committing the offset, Kafka will deliver the message again after recovery. Consequently, if the consumer crashes before committing, the same message will be reprocessed, leading to duplicate processing.
This delivery model is particularly suitable for applications where message loss is unacceptable but duplicates can be managed such as a notification service, where Kafka is used to deliver email alerts or push notifications, an at-least-once delivery model is perfectly acceptable, even if it leads to duplicate notifications being sent occasionally.
To implement at-least-once delivery effectively, it is recommended to set enable.auto.commit=false and use manual offset commits after successful processing to maintain control over message acknowledgment.
2. At-Most-Once Delivery Guarantee
In this delivery model, the consumer commits the offset before processing the message. This approach ensures that each message is processed at most once, but messages may be lost if the consumer fails during processing.
If the consumer crashes after committing the offset but before processing the message, Kafka assumes the message has already been processed and does not deliver it again. This can lead to message loss, as the consumer skips the unprocessed message upon recovery.
This delivery model is suitable for non-critical applications where message loss is acceptable, but duplicate processing is undesirable. For example, in logging systems or real-time metrics tracking, losing some data points is acceptable, but duplicates can distort results.
To implement at-most-once delivery effectively, set enable.auto.commit=true and ensure that the consumer reads the message and acknowledges it immediately without additional processing.
3. Exactly-Once Delivery Guarantee
In this the consumer commits the offset within a transactional context to ensure that each message is processed exactly once, with no duplicates or message loss. This requires both the producer and consumer to handle idempotent processing.
If the consumer crashes during message processing, Kafka ensures that the same message is not reprocessed multiple times by maintaining transactional integrity. Both the message processing and offset commit are done atomically, meaning that either both succeed or both fail.
This delivery model is essential for mission-critical systems where neither duplicates nor message loss can be tolerated. For example, in financial transaction systems, processing a message twice or missing a message could cause serious errors.
This is a bit tricky as compared to the other two as it requires coordination between the producer and consumer. Following are the configurations to achieve this
- Producer :- Enable idempotent producer with
enable.idempotence=trueand settransactional.idin the producer configuration for transactional writes. - Consumer :- Use
isolation.level=read_committedin the consumer configuration to read only committed messages and setenable.auto.commit=falseto handle offset commits manually within transactions.
# -----------------------------------
# Kafka Consumer Configuration
# -----------------------------------
# **Bootstrap Servers:** A list of broker addresses used to establish the initial connection to the Kafka cluster.
bootstrap.servers=localhost:9092 # (No default)
# **Group ID:** Identifies the consumer group of which this consumer is a part.
group.id=consumer-group-1 # (No default)
# **Auto Offset Reset:** Determines what to do when there is no initial offset or if the current offset is invalid.
# Options: "latest" (default), "earliest", "none"
auto.offset.reset=latest # default: latest
# **Enable Auto Commit:** Enables or disables automatic offset commits.
enable.auto.commit=true # default: true
# **Auto Commit Interval (ms):** The frequency in milliseconds for auto-committing offsets if `enable.auto.commit` is true.
auto.commit.interval.ms=5000 # default: 5000 ms (5 seconds)
# **Session Timeout (ms):** The timeout used to detect consumer failures.
session.timeout.ms=10000 # default: 10000 ms (10 seconds)
# **Heartbeat Interval (ms):** The interval at which the consumer sends heartbeats to the broker.
heartbeat.interval.ms=3000 # default: 3000 ms (3 seconds)
# **Max Poll Records:** The maximum number of records returned in a single poll() call.
max.poll.records=500 # default: 500
# **Max Poll Interval (ms):** The maximum allowed time between calls to `poll()` before the consumer is considered unresponsive.
max.poll.interval.ms=300000 # default: 300000 ms (5 minutes)
# **Fetch Min Bytes:** The minimum amount of data the broker should return for a fetch request.
fetch.min.bytes=1 # default: 1 byte
# **Fetch Max Bytes:** The maximum amount of data the consumer can fetch per partition in one request.
fetch.max.bytes=52428800 # default: 50 MB
# **Fetch Max Wait (ms):** The maximum time the broker will wait before returning data if the fetch request size is not met.
fetch.max.wait.ms=500 # default: 500 ms
# **Key Deserializer:** Deserializer class for converting key bytes to objects.
key.deserializer=org.apache.kafka.common.serialization.StringDeserializer # default: (no default)
# **Value Deserializer:** Deserializer class for converting value bytes to objects.
value.deserializer=org.apache.kafka.common.serialization.StringDeserializer # default: (no default)
# **Partition Assignment Strategy:** Strategy for assigning partitions to consumers in the group.
partition.assignment.strategy=org.apache.kafka.clients.consumer.RangeAssignor # default: RangeAssignor
# **Isolation Level:** Determines how transactional records are read. Options: "read_uncommitted", "read_committed"
isolation.level=read_uncommitted # default: read_uncommitted
# **Retries:** Number of retries the consumer will attempt if there are transient failures.
retries=0 # default: 0 (no retries)
# **Client ID:** An identifier for the client, used for logging and monitoring purposes.
client.id=consumer-client-1 # default: (empty string)
# **Request Timeout (ms):** The maximum time the consumer will wait for a broker response before timing out.
request.timeout.ms=305000 # default: 305000 ms (5 minutes)
# **Connections Max Idle (ms):** The maximum time the consumer connection can be idle before being closed.
connections.max.idle.ms=540000 # default: 540000 ms (9 minutes)
# **Interceptor Classes:** List of interceptor classes to use for custom logic during message consumption.
interceptor.classes= # default: (empty)
# **Metrics Sample Window (ms):** Time window for each sample in consumer metrics.
metrics.sample.window.ms=30000 # default: 30000 ms (30 seconds)
# **Max Partition Fetch Bytes:** Maximum amount of data per partition per fetch request.
max.partition.fetch.bytes=1048576 # default: 1 MB
# **Receive Buffer Bytes:** Size of the TCP receive buffer (SO_RCVBUF).
receive.buffer.bytes=65536 # default: 65536 bytes (64 KB)
# **Send Buffer Bytes:** Size of the TCP send buffer (SO_SNDBUF).
send.buffer.bytes=131072 # default: 131072 bytes (128 KB)
# **Reconnect Backoff Max (ms):** Maximum time between successive reconnect attempts to the broker.
reconnect.backoff.max.ms=1000 # default: 1000 ms (1 second)
# **Reconnect Backoff (ms):** Initial time between reconnect attempts to the broker.
reconnect.backoff.ms=50 # default: 50 ms
# **Retry Backoff (ms):** Time to wait before retrying a failed fetch request.
retry.backoff.ms=100 # default: 100 ms
# **Allow Auto Create Topics:** Allows consumers to automatically create topics when they do not exist.
allow.auto.create.topics=true # default: true5Kafka Server/Broker
As you know by now the broker is a distributed commit log system where it manages the storage, distribution, and data in Kafka. It receives messages from producers, assigns offsets, stores the messages in topics and partitions, and serves read requests from consumers.
Kafka follows a leader-follower topology, similar to a master-slave model but more fault-tolerant and distributed. Data is stored as partitions within topics, and the cluster consists of N brokers. Each broker holds either the leader copy (primary) or a follower copy (replica) of the partition data.
Unlike traditional master-slave models where one master manages everything, Kafka’s leadership is distributed across brokers. A broker can be a leader for some partitions and a follower for others, balancing the load. The leader broker handles all reads and writes for its partitions, while followers replicate the data to stay in sync. If a leader broker fails, one of the followers is elected as the new leader.
Kafka Broker Discovery
This section will discuss how Kafka brokers are added to the system, how they are managed, how brokers identify each other, and how clients discover brokers. ZooKeeper or KRaft plays an important role in the discovery process. We will explain the details of these processes in the next section.
When a broker starts, it retrieves its broker ID from the broker.id property in server.properties. If the value is set to -1, the ID is auto-generated. The broker also reads the log directory specified by log.dirs to determine where partition data will be stored.
In a ZooKeeper-based cluster, the broker registers itself with ZooKeeper by creating an ephemeral node. ZooKeeper tracks active brokers through these ephemeral nodes. If a broker crashes or becomes unresponsive, its corresponding node is deleted, notifying the system of the broker’s unavailability.
In a KRaft-based cluster, the broker registers itself with the active controller in the controller quorum by sending a registration request. The controller keeps track of active brokers and updates the KRaft metadata log with the broker’s details, such as its ID, host, and port. Unlike ZooKeeper’s ephemeral nodes, the controller uses heartbeat mechanisms to monitor broker availability.
When a broker starts, it fetches the cluster metadata from ZooKeeper or the KRaft controller to understand the current state of the cluster. It learns which partitions it is responsible for as a leader or follower. Follower brokers periodically pull data from the leader broker to stay in sync and maintain consistent replicas.
Brokers also exchange heartbeats to indicate they are active and functioning properly. In the event of a leader broker failure, the controller detects the issue and reassigns the partition leadership to a new broker. To ensure consistency, brokers synchronize their logs based on the latest offset positions during failover.
Producers and consumers need to connect to brokers to send or fetch data. They connect to one of the servers mentioned in the bootstrap.servers configuration.
bootstrap.servers=broker1:9092,broker2:9092
Then the producer/consumer sends a Metadata Request to the bootstrap broker to retrieve the list of all brokers in the cluster and the leader broker for each partition.
When it comes to Kafka servers, here are some key items to keep in mind, along with their roles.
- Leader
A leader in Kafka is the broker responsible for handling all read and write requests for a specific partition. Each partition within a topic has one leader at any given time. The leader broker ensures that messages are written to disk and replicated to the follower brokers for fault tolerance.
In case the leader broker for a partition fails, the controller reassigns one of the in-sync replicas (ISRs) as the new leader to ensure continuity. For example, if a topic order_events has three partitions, each partition will have its own leader broker to distribute the load across the cluster.
- ZooKeeper-based: The leader for a partition is selected by the controller broker (which uses ZooKeeper for leader election and metadata synchronization). ZooKeeper stores the metadata about which broker is the leader for each partition.
- KRaft-based: The controller quorum (which consists of a set of brokers) manages partition leader elections. The active controller in the quorum assigns the leader and replicates the metadata logs internally without involving ZooKeeper.
- Controller
The controller is a special broker in the Kafka cluster responsible for managing the overall cluster state and partition leadership. When a broker starts, one broker is elected as the controller. The controller handles various important tasks, such as leader elections, where it assigns brokers as leaders for partitions, and broker failover management, where it detects broker failures and reassigns partitions to other brokers.
It also manages partition rebalancing to ensure that partitions are evenly distributed across the brokers. The controller itself does not handle read or write requests but plays a crucial role in maintaining the cluster’s metadata and ensuring proper coordination.
- ZooKeeper-based: The controller is a broker elected via ZooKeeper to manage cluster metadata. The controller assigns partition leaders, triggers failovers, and handles rebalances.
- KRaft-based: In KRaft, there is no ZooKeeper. Instead, the controller role is handled by the controller quorum (a group of brokers). The active controller in the quorum performs the same tasks as the ZooKeeper-based controller but stores metadata in the KRaft log replicated across the quorum for fault tolerance.
In ZooKeeper, only one broker is the controller, but in KRaft, multiple brokers participate in the quorum, providing distributed consensus.
- In-Sync Replica (ISR)
An in-sync replica (ISR) is a replica of a partition that is up-to-date with the leader broker. The ISR set includes the leader broker and all follower brokers that have fully replicated the latest data from the leader. A replica is removed from the ISR set if it falls significantly behind the leader based on the configurationreplica.lag.time.max.ms.
Kafka only considers a write successful when the number of replicas in the ISR that acknowledge the message meets or exceeds the value ofmin.insync.replicas. This configuration defines the minimum number of replicas (including the leader) that must be in sync for a write to be accepted whenacks=allis set. If fewer replicas are available, the broker rejects the write request to avoid potential data loss.
Example: For a topic withmin.insync.replicas=2and a replication factor of 3, if only one replica (leader) is available and the others fall out of sync, the producer will receive an error ifacks=allis set. This ensures that data is not acknowledged unless a minimum number of replicas hold the latest copy. - Follower
A follower is a broker that holds a replica of the data for a partition but does not handle read or write requests. Followers periodically pull data from the leader broker to stay in sync with the latest state. In the event of a leader broker failure, one of the followers is promoted to become the new leader for that partition. If a follower broker falls too far behind in replicating data from the leader, it may be removed from the ISR set to maintain data consistency.
- ZooKeeper-based: Follower brokers fetch data from the leader broker and update ZooKeeper to indicate they are in sync.
- KRaft-based: Follower brokers report their status directly to the controller quorum, which logs their progress.
- Group Coordinator
The group coordinator is a broker responsible for managing consumer group membership and partition assignments. When a consumer joins a consumer group, the group coordinator assigns partitions to the consumer based on the partition assignment strategy (such as Range, RoundRobin, or Sticky).
The group coordinator tracks consumer heartbeats to detect when consumers join or leave the group. In case a consumer fails or disconnects, the group coordinator triggers a rebalance to reassign the partitions of the failed consumer to the remaining active consumers in the group.
- ZooKeeper-based: The group coordinator assigns partitions to consumers in a consumer group and updates ZooKeeper with the assignment details.
- KRaft-based: The group coordinator role remains the same but relies on the KRaft metadata log instead of ZooKeeper for maintaining the state.
- Transaction Coordinator
The transaction coordinator manages transactional messages in Kafka to ensure that all messages within a transaction are either committed or aborted. It tracks the status of ongoing transactions by maintaining the transaction state and writes transaction markers (such as commit or abort markers) in the log to indicate the outcome of the transaction.
The transaction coordinator ensures that producers can write messages atomically across multiple partitions and that consumers only read committed messages whenisolation.level=read_committedis set.
- ZooKeeper-based: The transaction state is updated in ZooKeeper to maintain consistency.
- KRaft-based: The transaction state is managed and logged directly within the KRaft log, ensuring strong consistency across controllers.
Kafka data storage
As we already know, data in Kafka is categorized into topics, and each topic is further divided into multiple partitions, which are the units of parallelism in Kafka. Each partition is an append-only log where messages are written sequentially. The replication factor defines how many copies of each partition exist across the cluster.
For example, if the replication factor is set to 3, there will be one leader and two followers for each partition.
- Replication factor = 1: No replication; if the broker fails, the data is lost.
- Replication factor = 2 or more: The data is replicated across multiple brokers for fault tolerance.
#############################
# General Broker Information
#############################
# Unique ID for the broker. Must be unique across brokers in the cluster.
broker.id=1 # Default: 0 (auto-generated if set to -1)
# Hostname or IP address the broker advertises to clients.
advertised.listeners=PLAINTEXT://localhost:9092 # Default: not set (commonly changed for client communication)
# List of host/port pairs to listen on.
listeners=PLAINTEXT://:9092 # Default: PLAINTEXT://:9092
########################
# Log (Data) Directories
########################
# Directories where Kafka stores log data (can specify multiple directories separated by commas).
log.dirs=/var/kafka/data # Default: /tmp/kafka-logs
# Maximum size of a log segment file before it is rolled.
log.segment.bytes=1073741824 # Default: 1GB
# Time interval after which a log segment is rolled even if not full.
log.roll.hours=168 # Default: 7 days (in hours)
# Maximum time to retain logs before deletion.
log.retention.hours=168 # Default: 7 days
# Maximum size of logs retained.
log.retention.bytes=-1 # Default: -1 (unlimited)
# Minimum age of log segments before deletion (compaction).
log.cleaner.min.cleanable.ratio=0.5 # Default: 0.5 (compaction is triggered if the ratio of retained data to total data exceeds this value)
# Number of threads for handling partition reassignment and data recovery.
num.recovery.threads.per.data.dir=4 # Default: 1
#####################
# Replication Settings
#####################
# Default replication factor for automatically created topics.
default.replication.factor=3 # Default: 1 (recommended to be set to 3 or more for fault tolerance)
# Minimum number of in-sync replicas required for a write to be acknowledged.
min.insync.replicas=2 # Default: 1 (recommended to be set to at least 2 for durability)
# Number of threads handling replication for fetching data from leaders.
num.replica.fetchers=4 # Default: 1 (increased for faster replication)
#######################
# Message Handling
#######################
# Maximum size of a message that the broker will accept.
message.max.bytes=1048576 # Default: 1MB
# Maximum batch size in bytes that the producer will send to the broker.
batch.size=16384 # Default: 16KB
# Time the broker waits for additional messages before sending a batch.
linger.ms=5 # Default: 0ms (commonly changed to optimize batch sending)
# Compression type used for messages. Options: "gzip", "snappy", "lz4", "producer".
compression.type=producer # Default: "producer" (follows the producer’s compression settings)
########################
# Consumer Group Settings
########################
# Maximum time before a consumer is considered dead if no heartbeat is received.
session.timeout.ms=10000 # Default: 10 seconds
# Time between consumer heartbeats.
heartbeat.interval.ms=3000 # Default: 3 seconds
# Maximum time between polls before a consumer is considered unresponsive.
max.poll.interval.ms=300000 # Default: 5 minutes
###################
# Security Settings
###################
# Protocol for inter-broker communication (PLAINTEXT, SSL, etc.).
security.inter.broker.protocol=SSL # Default: PLAINTEXT
# SSL keystore location and password (for secure communication).
ssl.keystore.location=/path/to/keystore # Default: not set
ssl.keystore.password=password # Default: not set
# SSL truststore location and password.
ssl.truststore.location=/path/to/truststore # Default: not set
ssl.truststore.password=password # Default: not set
###################
# Topic Management
###################
# Enable automatic topic creation when a producer or consumer references a non-existent topic.
auto.create.topics.enable=false # Default: true
# Enable automatic topic deletion.
delete.topic.enable=true # Default: false
####################
# Controller Quorum
####################
# Quorum configuration for KRaft-based clusters (used instead of ZooKeeper).
controller.quorum.voters=0@localhost:9093 # Default: not set (only for KRaft mode)
#####################
# Network Configuration
#####################
# Maximum size of a request (in bytes) that the broker will accept.
max.request.size=1048576 # Default: 1MB
# Maximum bytes the broker will accept for a client request.
socket.request.max.bytes=104857600 # Default: 100MB
#########################
# Quotas and Throttling
#########################
# Maximum bytes a producer can send per second.
producer.quota.window.num=1 # Default: not set (used for throttling)
#########################
# Log Compaction Settings
#########################
# Enable or disable log compaction (used for compacted topics).
log.cleaner.enable=true # Default: false
# Number of threads used for log compaction.
log.cleaner.threads=4 # Default: 1
######################
# Metadata and Timeouts
######################
# Time between metadata updates.
metadata.max.age.ms=300000 # Default: 5 minutes
# Timeout for broker-controlled shutdown (in milliseconds).
controlled.shutdown.timeout.ms=30000 # Default: 30 seconds
# Maximum retries for broker shutdown.
controlled.shutdown.max.retries=3 # Default: 3 retries
6ZooKeeper / KRaft
We have covered enough about what and where ZooKeeper/KRaft is used so far. Now, let’s dive deeper to understand how ZooKeeper and KRaft are involved in these tasks in detail. We will go through each process step-by-step and compare how ZooKeeper handles it versus how KRaft manages it.
Before we move on to the Kafka operations where ZooKeeper/KRaft is involved, let’s first cover the fundamentals of ZooKeeper and KRaft. This will help build a clear understanding of their roles and how they contribute to the overall functioning of Kafka.
Zookeeper Ensemble
This is a group of ZooKeeper servers (nodes) that work together to maintain the system’s state. Typically, an ensemble consists of an odd number of nodes (e.g., 3, 5, or 7) to ensure fault tolerance. It ensures that ZooKeeper itself is fault-tolerant. Even if some ZooKeeper nodes fail, the ensemble can still function as long as a majority (quorum) is available.

The following are the main components and features of ZooKeeper that we need to understand to comprehend its role in Kafka system management.
- ZNodes (ZooKeeper Nodes) : It is a data node in ZooKeeper’s hierarchical structure, similar to a file in a filesystem.
- Persistent ZNode
- These znodes remain in ZooKeeper even if the client that created them disconnects.
- Example in Kafka: Topic metadata and consumer group information.
- Ephemeral ZNode:
- These znodes are automatically deleted when the client that created them disconnects.
- Example in Kafka: Broker registration nodes (/brokers/ids/[id]) and the /controller node.
- Sequential ZNode:
- These znodes have a unique sequence number appended to their names upon creation, ensuring a globally unique name.
- Example in Kafka: Used during certain leader elections and generating unique IDs.
- Persistent ZNode
- Watch Mechanism : ZooKeeper clients can set watches on znodes to get notified when changes occur (such as when a znode is created, deleted, or updated).
- Example in Kafka:
- Brokers set a watch on the /controller znode to detect changes in the controller broker.
- Consumers set watches to detect changes in group membership and partition assignments.
- Relevance in Kafka: Watches enable real-time updates for brokers and clients, allowing quick reactions to events like controller elections, broker failures, and rebalancing.
- Example in Kafka:
- Data Consistency : ZooKeeper follows a strong consistency model, meaning that all reads and writes to znodes are consistent across the entire ZooKeeper ensemble.
- Relevance in Kafka: ZooKeeper’s strong consistency ensures that all brokers and clients get the latest metadata, preventing conflicting views of the cluster state.
- Relevance in Kafka: ZooKeeper’s strong consistency ensures that all brokers and clients get the latest metadata, preventing conflicting views of the cluster state.
- Atomic Updates and Transactions : ZooKeeper supports atomic updates, where changes to znodes are applied as a single, indivisible operation. It also supports multi-operation transactions, ensuring that multiple related updates either all succeed or all fail.
- Example in Kafka:
- During partition reassignments, ZooKeeper applies updates atomically to ensure consistency.
- Metadata updates, such as leader reassignments, are applied as transactions to avoid partial updates.
- Relevance in Kafka: Atomic updates and transactions help maintain a consistent state during complex operations, such as rebalances and leader elections.
- Example in Kafka:
KRaft (Kafka Raft)
KRaft (Kafka Raft) is Kafka’s ZooKeeper-less architecture introduced to eliminate the dependency on ZooKeeper and make Kafka self-sufficient for metadata management and cluster coordination. KRaft replaces ZooKeeper with an internal controller quorum that uses the Raft consensus protocol for leader elections and metadata replication. Below are the fundamental building blocks of KRaft and their relevance to Kafka:

- Controller Quorum : In KRaft, the controller quorum is a set of brokers that manage cluster metadata.
- Active Controller: One broker in the quorum is elected as the active controller to handle metadata updates and partition assignments.
- Follower Controllers: The remaining quorum members act as followers and replicate the metadata logs from the active controller.
Relevance in Kafka:The controller quorum is responsible for managing the leader election, partition assignment, and failover management, similar to what ZooKeeper did in the legacy architecture.
- Active Controller: One broker in the quorum is elected as the active controller to handle metadata updates and partition assignments.
- Metadata Log : KRaft uses a metadata log to store the entire cluster state.
- This log is replicated across all brokers in the controller quorum using the Raft consensus protocol.
- The metadata log contains:
- Broker registration data
- Topic and partition information
- Leader assignments
- Consumer group metadata
- Relevance in Kafka: Instead of relying on ZooKeeper for metadata storage, KRaft’s metadata log is internally replicated and highly consistent, ensuring all quorum members have the latest cluster state.
- This log is replicated across all brokers in the controller quorum using the Raft consensus protocol.
- Raft Consensus Protocol : The Raft protocol is a distributed consensus algorithm used for maintaining consistency among the controller quorum members.
The leader in the quorum proposes metadata updates.
- The updates are replicated to follower controllers, and once a majority (quorum) acknowledges, the update is committed.
- If the active controller fails, a new leader is elected from the quorum.
- Relevance in Kafka : Raft ensures that metadata updates are consistent across all quorum members and provides a mechanism for fault tolerance by electing a new leader when the active controller fails.
- The updates are replicated to follower controllers, and once a majority (quorum) acknowledges, the update is committed.
- Transaction Management : In KRaft, the transaction coordinator manages exactly-once semantics (EOS) by tracking the state of producer transactions.
- The transaction state (commit/abort) is written to the metadata log.
- Consumers with iso lation.level=read_committed can read only committed messages.
- Relevance in Kafka : KRaft handles transactions more efficiently by replicating transaction states across the quorum, ensuring durability and consistency.
- The transaction state (commit/abort) is written to the metadata log.
Kafka Operations: ZooKeeper vs KRaft Involvement
Let’s break down each Kafka operation and explain the role of ZooKeeper (legacy architecture) and KRaft (modern ZooKeeper-less architecture) in these operations. We will cover operations such as message production, consumer group coordination, leader elections, and broker registration, highlighting the differences between the two architectures.
- Broker Registration: When a broker starts, it registers itself with the cluster.
- ZooKeeper-based Kafka:
- The broker creates an ephemeral node under /brokers/ids/[broker-id] in ZooKeeper.
- This ephemeral node stores information such as the broker’s ID, host, port, and rack information.
- If the broker disconnects or fails, ZooKeeper deletes the ephemeral node, notifying the controller that the broker is no longer active.
- KRaft-based Kafka:
- The broker sends a BrokerRegistrationRequest to the controller quorum.
- The active controller logs the broker information in the metadata log.
- Heartbeat messages are used to detect broker liveness. If heartbeats fail, the broker is marked offline.
- Key Difference: ZooKeeper uses ephemeral nodes to track broker status, whereas KRaft relies on metadata logs and heartbeats.
- ZooKeeper-based Kafka:
- Controller Election: One broker in the cluster is elected as the controller to manage partition leadership and metadata.
- ZooKeeper-based Kafka:
- The first broker to create the /controller ephemeral node in ZooKeeper becomes the controller.
- If the controller broker fails, ZooKeeper deletes the node and triggers a new controller election.
- KRaft-based Kafka:
- The Raft consensus protocol is used to elect a new active controller from the controller quorum.
- The elected broker updates the metadata log to mark itself as the new active controller.
- Key Difference: ZooKeeper handles controller election using ephemeral nodes, while KRaft uses a distributed consensus mechanism (Raft) within the quorum.One broker in the cluster is elected as the controller to manage partition leadership and metadata.
- ZooKeeper-based Kafka:
- Leader Election for Partitions: A leader broker is assigned for each partition to handle read/write requests.
- ZooKeeper-based Kafka:
- The controller broker assigns a leader for each partition and updates ZooKeeper with the new leader information.
- ZooKeeper notifies the relevant brokers about the updated leader assignments.
- KRaft-based Kafka:
- The active controller assigns partition leaders and updates the metadata log.
- The assignment is replicated to all follower controllers for fault tolerance.
- Key Difference: ZooKeeper stores leader information in znodes, whereas KRaft stores it in the internal metadata log.
- ZooKeeper-based Kafka:
- Message Production (Producer Sending Messages): The producer sends a message to a specific partition of a topic.
- ZooKeeper-based Kafka:
- The producer queries ZooKeeper (via the broker) to fetch the leader broker for the target partition.
- The producer sends the message batch to the leader broker.
- The leader broker writes the message to disk and replicates it to in-sync replicas (ISRs).
- KRaft-based Kafka:
- The producer fetches metadata from the active controller (not ZooKeeper).
- The controller quorum provides the leader assignment details, and the producer sends the message to the appropriate leader broker.
- Key Difference: In ZooKeeper-based Kafka, metadata is stored in ZooKeeper, whereas KRaft provides metadata directly through the controller quorum.
- ZooKeeper-based Kafka:
- Consumer Group Coordination and Partition Assignment: When a consumer joins a consumer group, it is assigned partitions to consume from.
- ZooKeeper-based Kafka:
- The group coordinator broker assigns partitions to the consumer and updates the partition assignments in ZooKeeper.
- ZooKeeper tracks the group membership and notifies the group coordinator if a consumer joins or leaves.
- Consumers use this information to fetch their assigned partitions.
- KRaft-based Kafka:
- The group coordinator broker assigns partitions and logs the assignment in the metadata log.
- The active controller coordinates this process internally without external dependencies.
- Key Difference: ZooKeeper handles consumer group membership using persistent znodes, while KRaft uses the metadata log for consumer group tracking.
- ZooKeeper-based Kafka:
- Consumer Offset Tracking: The consumer commits offsets to track the last processed message.
- ZooKeeper-based Kafka:
- Offsets are stored in the __consumer_offsets internal Kafka topic (not ZooKeeper).
- ZooKeeper is not directly involved in offset tracking but plays a role in consumer rebalancing.
- KRaft-based Kafka:
- The offset commit process remains the same as in ZooKeeper-based Kafka, using the __consumer_offsets topic.
- However, consumer group membership and partition assignments are logged in the metadata log rather than ZooKeeper.
- Key Difference: Both architectures use the __consumer_offsets topic for offsets, but KRaft replaces ZooKeeper for consumer group membership and partition assignments.
- ZooKeeper-based Kafka:
- Transactional Message Handling: Kafka tracks transactions to ensure exactly-once semantics (EOS) for message processing.
- ZooKeeper-based Kafka:
- The transaction coordinator broker uses ZooKeeper to store transaction state information.
- Markers (commit or abort) are logged in the partition to indicate the transaction outcome.
- KRaft-based Kafka:
- The transaction coordinator logs the transaction state in the metadata log.
- Consumers with isolation.level=read_committed only read committed transactions.
- Key Difference:: ZooKeeper handles transaction state using znodes, while KRaft replicates transaction state in the metadata log.
- ZooKeeper-based Kafka:
- Rebalancing: When a broker or consumer joins or leaves the cluster, a rebalance is triggered.
- ZooKeeper-based Kafka:
- The controller broker detects changes in broker or consumer membership via ZooKeeper watches.
- The controller updates ZooKeeper with new leader assignments and consumer partition assignments.
- KRaft-based Kafka:
- The active controller detects membership changes through heartbeats.
- The controller updates the metadata log with new partition assignments.
- Key Difference: ZooKeeper relies on ephemeral nodes and watches for change detection, while KRaft uses heartbeat messages and the metadata log.
- ZooKeeper-based Kafka:
- Failover Handling: If a broker or consumer fails, Kafka reassigns partitions and elects new leaders.
- ZooKeeper-based Kafka:
- ZooKeeper deletes the ephemeral node for the failed broker, notifying the controller.
- The controller elects new leaders and updates ZooKeeper.
- KRaft-based Kafka:
- The active controller detects failure through missing heartbeats.
- New leaders are elected, and the metadata log is updated.
- Key Difference: ZooKeeper uses ephemeral nodes to detect failures, whereas KRaft relies on heartbeat timeouts.
- ZooKeeper-based Kafka:
Summary Table: Kafka Operations (ZooKeeper vs KRaft)
Operation | ZooKeeper-Based Kafka | KRaft-Based Kafka |
|---|---|---|
Broker Registration | Ephemeral nodes under /brokers/ids | Broker registration requests to controller quorum. |
Controller Election | Ephemeral node /controller | Raft-based consensus within the quorum. |
Leader Election | Managed by the controller using ZooKeeper | Managed by the active controller. |
Message Production | Leader information fetched from ZooKeeper | Leader information fetched from metadata log. |
Consumer Coordination | Membership tracked in ZooKeeper | Membership tracked in metadata log. |
Offset Tracking | __consumer_offsets topic (Kafka internal) | __consumer_offsets topic (unchanged). |
Transactions | Transaction state tracked in ZooKeeper | Transaction state tracked in metadata log. |
Rebalancing | Watches detect changes via ZooKeeper | Heartbeats detect changes via controller quorum. |
Failover Handling | Detected through ephemeral node deletion | Detected through heartbeat timeouts. |
##############################
# General ZooKeeper Settings
##############################
# The port on which ZooKeeper listens for client connections.
clientPort=2181 # Default: 2181 (commonly changed to avoid conflicts)
# The directory where ZooKeeper stores snapshot data.
dataDir=/tmp/zookeeper # Default: /tmp/zookeeper (commonly changed to persistent storage)
# The directory where ZooKeeper stores transaction logs.
dataLogDir=/tmp/zookeeper-logs # Default: same as dataDir (recommended to change for high performance)
#########################
# Session and Connection
#########################
# The maximum number of connections from a single client.
maxClientCnxns=60 # Default: 60 (can be increased based on client load)
# The maximum session timeout in milliseconds.
maxSessionTimeout=40000 # Default: 40,000 ms (commonly changed for client session reliability)
# The minimum session timeout in milliseconds.
minSessionTimeout=4000 # Default: 4,000 ms (ensures minimum wait time before session expiry)
########################
# Server Configuration
########################
# The number of tick intervals for an operation to time out.
tickTime=2000 # Default: 2,000 ms (sets the base time unit for session and heartbeat intervals)
# The number of ticks after which a session expires if no heartbeat is received.
initLimit=10 # Default: 10 ticks (used during leader election)
# The number of ticks within which followers must sync with the leader.
syncLimit=5 # Default: 5 ticks (used during leader sync to avoid delays)
# The ID for this ZooKeeper server (needed in an ensemble).
server.id=1 # Default: not set (must be unique in a ZooKeeper ensemble)
# The list of servers in the ZooKeeper ensemble.
# Format: server.<id>=<hostname>:<leader_port>:<election_port>
server.1=localhost:2888:3888
server.2=localhost:2889:3889
server.3=localhost:2890:3890
#######################
# Log and Snapshot Retention
#######################
# The maximum number of snapshots to retain.
snapCount=10000 # Default: 10,000 (commonly changed to avoid excessive disk usage)
# Time (in milliseconds) between ZooKeeper transaction log flushes.
autopurge.snapRetainCount=3 # Default: 3 (purges old snapshots)
# The time interval (in hours) for ZooKeeper to purge old logs and snapshots.
autopurge.purgeInterval=24 # Default: 24 hours
#########################
# Data Integrity and ACL
#########################
# Enable or disable snapshot checksum validation.
snapshotChecksum=true # Default: true (helps verify data integrity)
# Enforce authentication and access control lists (ACLs) for ZooKeeper nodes.
authProvider.sasl=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
# The quorum listens on this port for internal communication.
quorumListenOnAllIPs=false # Default: false (binds quorum to a single IP; set to true for all IPs)
#######################
# JMX and Monitoring
#######################
# Enable JMX monitoring for ZooKeeper.
jmx.local.only=false # Default: true (set to false for remote JMX monitoring)
######################
# ZooKeeper Client Limits
######################
# Maximum size of a ZooKeeper data packet.
jute.maxbuffer=4194304 # Default: 4MB (increase if storing large data on nodes)
###################
# Leader Election
###################
# The election algorithm to use.
electionAlg=3 # Default: 3 (Fast leader election algorithm)2. How Kafka is Fast and Near Real-Time? Digging Deep into Its Optimizations
Though we’ve got a solid understanding of how Kafka works and its design principles from the previous sections, one question may still linger in our minds: “All right, these optimizations make sense, but Kafka is still relying on secondary storage (disk). How can it possibly be this fast?“
So in this section, we will dive deeper into some of the key design choices Kafka has made to optimize performance. We’ll explore how Kafka leverages low-level system functionalities and fine-tunes storage mechanisms to make disk-based operations as efficient as possible. By doing so, Kafka achieves near real-time performance comparable to in-memory systems, while maintaining durability and scalability.
Since we are discussing the performance aspects, I will also list the performance optimization choices Kafka has made, which have been discussed in detail above. While there may be some overlap, I will summarize them at the end to provide a clear overview of all the performance improvements.
1. Sequential Disk Writes (Append-Only Logs)
Kafka’s approach to sequential disk writes is a key design feature that significantly enhances its performance. When Kafka writes data to disk, it does so in a sequential manner, which reduces the overhead associated with disk seek times. This is crucial because accessing data randomly on a disk can be much slower than accessing it sequentially due to the mechanical nature of traditional hard drives.
Let’s take a look at how it works.

- Log Structure:
- Kafka organizes data into topics, which are further divided into partitions. Each partition is treated as a log, where messages are appended sequentially. This means that when a producer sends a message, it is written to the end of the current segment file of the partition, ensuring that all writes happen in order.
- Kafka organizes data into topics, which are further divided into partitions. Each partition is treated as a log, where messages are appended sequentially. This means that when a producer sends a message, it is written to the end of the current segment file of the partition, ensuring that all writes happen in order.
- Segment Files:
- Each partition consists of multiple segment files of fixed size (e.g., 1GB). When the current segment reaches its size limit, it is closed, and a new segment file is created for subsequent writes. This method of appending data at the end of the file allows Kafka to leverage the efficiency of sequential disk access.
- Each partition consists of multiple segment files of fixed size (e.g., 1GB). When the current segment reaches its size limit, it is closed, and a new segment file is created for subsequent writes. This method of appending data at the end of the file allows Kafka to leverage the efficiency of sequential disk access.
- Performance Benefits:
- By writing data sequentially, Kafka minimizes the need for random disk seeks, which can be time-consuming. Sequential writes take advantage of the way disks read and write data more efficiently when accessed in order. This results in higher throughput and lower latency for both write and read operations.

2. Page Cache Usage (Memory-Mapped Files)
Kafka utilizes the operating system’s page cache to optimize data reading and writing, significantly enhancing performance. The page cache acts as an intermediary between the disk and the application, allowing Kafka to leverage memory for faster data access.
Let’s take a look at how it works.
- Data Writing:
- When producers send messages to Kafka, the data is first written to the page cache rather than directly to disk. This initial write is marked as “dirty,” indicating that it has not yet been persisted to the underlying storage. • By writing to the page cache, Kafka can avoid the latency associated with synchronous disk I/O operations, allowing for faster message ingestion.
- When producers send messages to Kafka, the data is first written to the page cache rather than directly to disk. This initial write is marked as “dirty,” indicating that it has not yet been persisted to the underlying storage. • By writing to the page cache, Kafka can avoid the latency associated with synchronous disk I/O operations, allowing for faster message ingestion.
- Data Reading:
- When consumers read messages from Kafka, they often fetch data directly from the page cache instead of reading from disk. This significantly speeds up read operations since accessing data in memory is much faster than accessing it on disk.
- If the requested data is not in the page cache (a cache miss), Kafka will then read from the disk, which can introduce latency.
- Flushing to Disk:
- Periodically, dirty pages in the cache are flushed to disk to ensure that data is not lost in case of a failure. This process is managed by the operating system and occurs based on various factors, such as memory pressure and system configuration.
- The flushing mechanism allows Kafka to balance between high performance (by utilizing memory) and durability (by ensuring data is eventually written to disk).
Benefits of Using Page Cache
By leveraging the page cache, Kafka significantly improves performance by minimizing disk I/O operations, leading to higher throughput and lower latency for both reads and writes. The page cache acts as a cost-effective in-memory caching solution that does not require any additional configuration or resources from Kafka itself. Additionally, since many read requests can be served directly from memory, it reduces the load on disk resources, enhancing overall system efficiency and longevity.
Potential Risks and Considerations
While using page cache improves performance, it also introduces some risks. If all replicas of a message fail before it is flushed to disk, there is a potential for data loss. Therefore, users must configure acknowledgment settings appropriately to ensure data durability.
3. Zero-Copy Transfer
The zero-copy transfer is an advanced data transfer technique used in Kafka to enhance performance by minimizing the number of data copies between memory regions during read-and-write operations. Leveraging modern operating system capabilities like the sendfile() system call, this method drastically reduces CPU overhead and increases throughput, making it particularly beneficial for high-performance, data-intensive applications.
Before going into detail, let’s first talk about how a traditional data transfer happens without this zero-copy optimization.
Without Zero-Copy
The following image shows how the data gets transferred without Zero-Copy
Producer flow
- Producer writes data to NIC buffer of broker
- NIC to the Socket buffer using DMA (Direct memory access – No CPU involvement )
- The broker application performs a
read()system call to fetch the data from the socket buffer to the Application buffer. - The broker then performs a
write()system call to write the data from the Application buffer to the OS buffer AKA Page Cache - Then from the OS buffer to the HDD using the DMA
Consumer flow
- Data is fetched from the HDD to the OS buffer using DMA.
- Again another
read()call to copy data from the OS buffer to the Application buffer - Then the broker will perform a
write()system call to copy the data from the Applicaion buffer to the Socket buffer - DMA is used to copy the data from the Socket buffer to NIC
- Then data is transferred to the consumer for consumption.
With Zero-Copy
In zero-copy, the producer’s operations remain unaffected and behave like normal. The producer is responsible for sending data to the Kafka broker; this process does not directly leverage zero-copy. Zero-copy is only applicable on the Kafka broker side, that too only consumer data retrieval.
Consumer flow
- Data is fetched from the HDD to the OS buffer using
- Then the broker will perform a
sendfile()system call to copy the data from the OS buffer to the Socket buffer - DMA is used to copy the data from the Socket buffer to NIC
- Then data is transferred to the consumer for consumption.
Why Is It Called Zero-Copy? (Most People Get This Wrong)
If you carefully observe, data is still being copied between HDD → OS Buffer → Socket Buffer → NIC Buffer so why is it still called Zero-Copy? The reason is that no data is copied to or from user space during the process. This is why it is referred to as Zero-Copy (in User Space). By avoiding user space entirely, this approach significantly reduces the context switches between user space and kernel space, as well as the data transfers between the OS and User space
In some articles, it is stated that the sendfile() call copies data directly from the OS buffer to the NIC buffer, this is incorrect. The socket buffer cannot be skipped, as it is a critical part of the TCP/IP stack. The socket buffer is essential for adhering to the protocol, as it ensures that the necessary headers and metadata are added at the transport layer before the data is sent to the NIC buffer for transmission.
Two things to note here which make the data transfer pretty fast
- Direct Memory Access (DMA):
- This mechanism allows hardware devices (like disk controllers or Network Interface Cards, NICs) to transfer data directly to or from the system’s main memory (RAM), bypassing the CPU. This improves performance by freeing up the CPU from handling data transfer tasks, enabling it to focus on other computations.
- This mechanism allows hardware devices (like disk controllers or Network Interface Cards, NICs) to transfer data directly to or from the system’s main memory (RAM), bypassing the CPU. This improves performance by freeing up the CPU from handling data transfer tasks, enabling it to focus on other computations.
- sendfile() System Call:
- This call allows the operating system to send data directly from a file descriptor (representing a file on disk) to a socket (representing a network connection) without involving the application in the copying process.
Now let’s summarize all the optimizations we have discussed across the sections so far.
- Sequential Writes: Ensures efficient disk I/O by appending data sequentially to logs.
- Zero Data Overwrite: Never modifies messages once they are written to disk. This avoids expensive seek operations and reduces contention on disk.
- Zero-Copy: Minimizes CPU usage by avoiding user-space memory copies during data transfer.
- Log Segmentation: Splits logs into manageable segments for easier retention and cleanup.
- Page Cache: Utilizes OS-level memory caching to reduce disk access and improve performance.
- Low Memory usage: Kafka avoids holding messages in JVM heap space to reduce Garbage Collection (GC) pauses, instead relying on the file system cache.
- Long Polling: Reduces idle cycles by allowing consumers to wait for new data more efficiently.
- Message Batching: Groups messages to optimize network and disk throughput.
- Compression: Reduces message size for efficient storage and faster data transfer.
- DMA (Direct Memory Access): Transfers data directly between hardware and memory, bypassing the CPU.
- Parallelism Using Partitions: Enables high scalability and throughput by allowing parallel processing.
3. Getting Started with Kafka: A Quick Hands-On Walkthrough
Since a detailed hands-on session is beyond the scope of this blog, we’ll quickly cover some basic steps to help you understand how to work with Kafka in real-world scenarios. This section will show you how to start the Kafka server, use the producer and consumer, and explore some key properties mentioned earlier. Additionally, we’ll demonstrate how to validate these configurations, providing you with a practical starting point for your Kafka journey.
1. Terminal-Based Kafka Setup and Usage
The steps below are based on a MacBook, using Homebrew for the installation.
1Install Homebrew (if not already installed)
# install home brew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
#Verify Homebrew installation:
brew --version
2Install Kafka Using Homebrew
# Update Homebrew
brew update
# Install Kafka
brew install kafka
# Verify Kafka Installation
kafka-topics --version
3Start Zookeeper (Required by Kafka)
# Start Zookeeper
zookeeper-server-start /opt/homebrew/etc/kafka/zookeeper.properties
OR
# Start Zookeeper in the foreground
zookeeper-server-start -daemon /opt/homebrew/etc/kafka/zookeeper.properties
OR
#using brew services, no need to pass any properties file
brew services start zookeeper
Typical zookeeper properties would look like below.
# Directory to store Zookeeper snapshots
dataDir=/tmp/zookeeper
# Port Zookeeper listens on
clientPort=2181
# Max client connections
maxClientCnxns=60
# Tick time (heartbeat interval in ms)
tickTime=2000
# Number of ticks for an initial synchronization
initLimit=10
# Number of ticks to allow between heartbeats
syncLimit=5
4Start Kafka Broker
# Start Kafka server
kafka-server-start /opt/homebrew/etc/kafka/server.properties
OR
# Start Kafka server in the foreground
kafka-server-start -daemon /opt/homebrew/etc/kafka/server.properties
OR
#using brew services, no need to pass any properties file
brew services start kafka
Typical server properties would look like below.
# Broker ID
broker.id=0
# Network Settings
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://localhost:9092
num.network.threads=3
num.io.threads=8
# Log and Storage Settings
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
# Zookeeper Connection
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=18000
# Group Coordinator
group.initial.rebalance.delay.ms=0
5Create Topic
# Create topic
kafka-topics --create --topic scribbled-tech-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
#List topic
kafka-topics --list --bootstrap-server localhost:9092
6Produce Message
kafka-console-producer --broker-list localhost:9092 --topic scribbled-tech-topic
Type some messages and press Enter after each message to send it to broker.
7ConsumeMessage
kafka-console-consumer --bootstrap-server localhost:9092 --topic test-topic --from-beginningWe can see messges getting consumed as and when we type some message in the producer window and press enter.
8Stop Kafka and Zookeeper
#Stop Kafka
kafka-server-stop
OR
#Stop kafka using brew if you used brew to start
brew services stop kafka
#Stop Zookeeper
zookeeper-server-stop
OR
#Stop Zookeeper using brew if you used brew to start
brew services stop zookeeper
The following is a short video recording of the Kafka terminal exercise using above commands.
2. Java-based Kafka clients
In the above section, we explored how to create topics, send messages using a producer, and consume messages using a consumer after installing and starting Kafka in the terminal. In this section, we will explore how Kafka is used in real-world scenarios with a programming language.
I will use Java Spring boot here, as it is one of the most prominent languages and frameworks currently used in the market. The concept remain same for all other languages and frameworks.
Java Producer
following are the producer application folder structure and its content
kafka_producer/
│
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ └── scribbledtech/
│ │ │ ├── controller/
│ │ │ │ └── KafkaController.java
│ │ │ ├── service/
│ │ │ │ └── KafkaProducerService.java
│ │ │ └── SpringKafkaProducerApplication.java
│ │ └── resources/
│ │ └── application.yaml
│ └── test/
│
├── pom.xml
└── README.md (optional)
Adding spring boot kafka dependency
<dependencies>
<!-- Spring Boot Starter for Kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- Spring Boot Starter Web for REST APIs -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
Configuring common producer properties in the application.yaml. Any topic-specific configurations will be handled separately in the Java code, while this serves as the default configuration for general use.
server:
port: 8083
spring:
kafka:
bootstrap-servers: localhost:9092 # Kafka broker addresses
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer # Serialize keys as strings
value-serializer: org.apache.kafka.common.serialization.StringSerializer # Serialize values as strings
retries: 5 # Number of retries for failed sends (useful for transient errors)
batch-size: 32768 # Size of a batch in bytes (e.g., 32 KB). Larger batches improve throughput but increase latency
buffer-memory: 67108864 # Total memory (in bytes) for buffering unsent records (default: 32 MB, here: 64 MB)
acks: all # Acknowledgment level: 'all' ensures all replicas confirm the message for durability
compression-type: gzip # Compression for records (options: none, gzip, snappy, lz4, zstd)
linger-ms: 10 # Wait time (in ms) before sending a batch. Higher values improve batching but add latency
max-request-size: 2097152 # Maximum size (in bytes) of a single message (e.g., 2 MB here)
request-timeout-ms: 20000 # Time (in ms) to wait for the broker's response before retrying or failing
delivery-timeout-ms: 30000 # Total time (in ms) allowed for retries and sending the record before failing
properties:
enable.idempotence: true # Ensures exactly-once delivery for messages (recommended for retries)
transactional.id: my-transaction-id # Enables transactional messaging (useful for atomic writes across topics/partitions)Now let’s look at the actual piece of code that sends the message
package com.scribbledtech.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service
public class KafkaProducerService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
private static final String TOPIC = "scribbled-tech-topic"; // Topic name
@Transactional
public void sendMessage(String key, String message) {
kafkaTemplate.executeInTransaction(operations -> {
operations.send(TOPIC, key, message);
System.out.println(String.format("Produced message: key=%s, value=%s", key, message));
return null;
});
}
}Let’s create a rest resource for posting the message, this is to trigger the message sending using a REST API.
package com.scribbledtech.controller;
import com.scribbledtech.service.KafkaProducerService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class KafkaController {
@Autowired
private KafkaProducerService kafkaProducerService;
@PostMapping("/send")
public String sendMessage(@RequestParam("key") String key, @RequestParam("message") String message) {
kafkaProducerService.sendMessage(key,message);
return "Message sent successfully key: " +key+" message : "+ message;
}
}Let create an entry point for the application ie; A spring bootstrap class
package com.scribbledtech;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SpringKafkaProducerApplication {
public static void main(String[] args) {
SpringApplication.run(SpringKafkaProducerApplication.class, args);
}
}
Java Consumer
kafka_producer/
│
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ └── scribbledtech/
│ │ │ ├── service/
│ │ │ │ └── KafkaConsumerService.java
│ │ │ └── SpringKafkaConsumerApplication.java
│ │ └── resources/
│ │ └── application.yaml
│ └── test/
│
├── pom.xml
└── README.md (optional)Maven dependency is very similar to that of Producer
<dependencies>
<!-- Spring Boot Starter for Kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- Spring Boot Starter Web for REST APIs -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>Like producer the below application.yaml conifigurations serves as the default configuration for general use. Any specific configurations will be handled separately in the Java code.
server:
port: 8082
spring:
kafka:
bootstrap-servers: localhost:9092 # Kafka broker addresses
consumer:
group-id: scribbled-tech-consumer-group # Consumer group ID
auto-offset-reset: earliest # Reset behavior (earliest, latest, none)
enable-auto-commit: true # Enable automatic offset committing
auto-commit-interval: 1000 # Interval (in ms) to commit offsets automatically
max-poll-records: 500 # Maximum records to fetch in a single poll
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
fetch-min-size: 1 # Minimum amount of data (in bytes) for a poll request
fetch-max-wait: 500 # Maximum time (in ms) the broker waits before sending data
max-poll-interval: 300000 # Maximum time between poll() calls before a rebalance
heartbeat-interval: 3000 # Frequency of heartbeat requests to the broker
session-timeout: 10000 # Time (in ms) to detect a consumer crash
isolation-level: read_committed # Visibility of transactional records (read_uncommitted/read_committed)
properties:
specific.consumer-property: value # Additional Kafka-specific consumer properties@KafkaListener used for configuring the consumer
package com.scribbledtech.service;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
public class KafkaConsumerService {
@KafkaListener(topics = "scribbled-tech-topic", groupId = "scribbled-tech-consumer-group")
public void consume(ConsumerRecord<String, String> record) {
System.out.println(String.format("Consumed message: key=%s, value=%s, partition=%d, offset=%d",
record.key(), record.value(), record.partition(), record.offset()));
}
}Spring boot entry class
package com.scribbledtech;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SpringKafkaConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(SpringKafkaConsumerApplication.class, args);
}
}
Testing
For testing first we need to start the zookeeper and kafka
brew services start zookeeper
brew services start kafkaStart the Producer and consumer running following command in the respective project folders
📂 kafka_producer → mvn spring-boot:run📂 kafka_consumer → mvn spring-boot:run
After starting the producer and consumer, the producer is running on port 8083 and can be invoked via the API ‘/send‘ to produce messages, while the consumer is already running and continuously polling messages from the Kafka server.
📂 kafka → curl -i --request POST 'localhost:8083/send?key=key1&message=postman'
HTTP/1.1 200
Content-Type: text/plain;charset=UTF-8
Content-Length: 53
Date: Mon, 27 Jan 2025 05:49:21 GMT
Message sent successfully key: key1 message : postmanProduced message: key=key1, value=postmanConsumed message: key=key1, value=postman, partition=0, offset=48
We can experiment with different configurations and start multiple consumers to consume the same topic, either with the same consumer group or different consumer groups, to understand the consumption pattern and partition logic. Since this blog is intended to provide a brief hands-on overview, these topics are beyond its scope, but you can explore them as an exercise.
4. Best Practices for High-Throughput Message Production
This section will summarize key points to keep in mind when aiming to improve throughput. These are all suggestions that can help, but it’s crucial to analyze the use case thoroughly to determine whether these techniques are feasible. If not implemented carefully, they may backfire.
The details of all these points have been explained in the previous section. Here, we will discuss the techniques along with their trade-offs, allowing you to make an informed decision about whether to adopt them.
- Batch Size –
batch.size
- How to Improve: Increase batch.size to allow more records to be grouped together in a single network request. This reduces network overhead and improves throughput.
- Trade-Off: Larger batch sizes consume more memory and increase latency, as the producer waits to fill the batch.
- Linger Time –
linger.ms
- How to Improve: Set a decent value for linger.ms (e.g., 5-10 ms) to allow the producer to accumulate more messages before sending. This enhances batching efficiency and throughput.Trade-Off: Introducing linger time adds a slight delay, which may not be suitable for applications needing low-latency messaging
- Compression Type –
compression.type- How to Improve: Use compression (e.g., gzip, snappy, lz4) to reduce message size, optimize network bandwidth, and improve throughput.
- Trade-Off: Compression increases CPU usage, especially with higher compression ratios (e.g., gzip).
- Acknowledgments –
acks
- How to Improve: For maximum throughput, use acks=1 (leader-only acknowledgment).
- Trade-Off: Lower acknowledgment levels may result in data loss if the leader crashes before syncing with replicas. Use acks=all for stronger durability at the cost of throughput.
- Retries and Idempotence –
retriesenable.idempotence
- How to Improve: Set retries to a high value (e.g., 5-10) to handle transient failures and enable enable.idempotence=true to prevent duplicate messages during retries.
- Trade-Off: Higher retries increase latency, and enabling idempotence slightly affects throughput due to added checks for exactly-once delivery.
- Buffer Memory –
buffer.memory
- How to Improve: Increase buffer.memory (e.g., 64 MB) to allow the producer to handle larger bursts of messages without blocking.
- Trade-Off: Larger buffer sizes require more memory and may block if the producer can’t send messages fast enough due to broker bottlenecks.
- Max Request Size –
max.request.size
- How to Improve: Increase max.request.size (e.g., 2 MB or more) to accommodate larger messages or batches. This prevents errors when sending large payloads.
- Trade-Off: Larger maximum request sizes increase broker load and can reduce throughput if improperly tuned for large batches.
- Partitions
- How to Improve: Increase the number of partitions in a topic to allow better parallelism across producers and consumers, improving overall throughput.
- Trade-Off: More partitions increase the broker’s load (metadata and replication) and can complicate consumer processing.
- Asynchronous Sending
- How to Improve: Use asynchronous send() calls to avoid blocking the producer thread, allowing it to handle more records in less time.
- Trade-Off: Asynchronous operations are harder to debug, and error handling requires callbacks, which can increase complexity.
- Number of network threads and number of IO threads –
num.network.threadsnum.io.threads
- How to Improve: Increase the number of network and I/O threads to handle more client connections and disk operations, improving broker efficiency.
- Trade-Off: Allocating too many threads can consume excessive system resources, potentially impacting other broker operations.
- Consumer Fetch Settings –
fetch.min.bytesfetch.max.wait.ms
- How to Improve: Adjust fetch.min.bytes to ensure consumers fetch enough data in each request, and set fetch.max.wait.ms to control how long consumers wait before polling.
- Trade-Off: Setting fetch values too high can increase latency, while low values can cause unnecessary network overhead.
- Socker buffer size –
socket.send.buffer.bytessocket.receive.buffer.bytes
- How to Improve: Increase the socket buffer sizes to handle larger traffic loads, preventing delays caused by insufficient buffer space during high-volume operations.
- Trade-Off: Larger buffers consume more memory and may require tuning to avoid overloading the broker.
- KRaft Metadata Timeout Settings
- How to Improve: Adjust KRaft timeout settings for leader elections and metadata updates to optimize Kafka’s metadata handling, especially during leader elections.
- Trade-Off: Setting timeouts too short can cause unnecessary reassignments, while overly long timeouts may delay leader elections.
- Optimize Disk I/O –
log.dirs
- How to Improve: Distribute log data across multiple physical disks by configuring multiple directories in log.dirs. This prevents disk bottlenecks and improves overall I/O performance.
- Trade-Off: Managing multiple disks can increase administrative overhead, and unbalanced data distribution can still cause performance issues.
- Set the Right Replication Factor
- How to Improve: Increase the replication factor for critical data to ensure durability, while lowering it for less important topics to save resources.
- Trade-Off: Higher replication factors increase broker disk and network load, so balance durability with resource constraints.
5. Event Sourcing with Kafka: Patterns and Anti-Patterns
Event Sourcing is a design pattern where the state of an application is derived by replaying a sequence of events from an event log. Apache Kafka, being a distributed event streaming platform, is often an excellent choice for implementing event sourcing due to its durability, scalability, and replayability features.
Below, we’ll discuss patterns and anti-patterns for implementing event sourcing with Kafka.
Patterns for Event Sourcing with Kafka
1Use Kafka Topics as Event Streams
- Pattern: Model each topic as an event stream where each message represents a single event in the system (e.g., OrderCreated, OrderUpdated, OrderCancelled).
- Why it works: Kafka topics naturally serve as an immutable log of events, allowing you to replay them to rebuild the state.
- Example:
- Topic: orders
- Events: OrderCreated, OrderPaid, OrderShipped
2Leverage Kafka Partitions for Parallelism
- Pattern: Partition topics based on a key, such as an entity ID (e.g., orderId).
- Why it works: This ensures all events for a single entity are processed in order within the same partition, preserving consistency while enabling parallelism across partitions.
- Example:
- Partition key: orderId
- Guarantees ordered processing for a specific orderId.
3Store Event Versions
- Pattern: Include a version number in your event payload.
- Why it works: Helps in maintaining backward compatibility and allows consumers to handle events from older schemas.
- Example:
{
"eventType": "OrderCreated",
"eventVersion": "1.0",
"data": { "orderId": "123", "customer": "John Doe" }
}
4Compact Topics for Snapshot Events
- Pattern: Use Kafka’s log compaction feature to retain only the latest event for a given key when dealing with snapshots or aggregates.
- Why it works: Reduces storage requirements for topics that only need the latest state of an entity.
- Example:
- Use compaction for a topic like user_profiles to store the latest user data.
5Use Kafka Streams for State Rebuilding
- Pattern: Use Kafka Streams to process events and materialize the state (e.g., tables in a database or in-memory state stores).
- Why it works: Kafka Streams offers tools like KTable and join for aggregating and transforming events efficiently.
- Example:
- Consume OrderCreated and OrderUpdated events and materialize the current order state.
6Event Retention and Replayability
- Pattern: Configure Kafka topics with long retention periods or infinite retention for critical event streams.
- Why it works: Ensures that events can be replayed to rebuild state for new consumers or recover from failures.
- Example:
- Set retention.ms=-1 for critical event logs like audit_logs.
7Schema Evolution with Avro/Protobuf
- Pattern: Use Avro or Protobuf schemas with a schema registry to manage changes in event formats.
- Why it works: Ensures compatibility between producers and consumers while enabling schema evolution.
- Example:
- Add new optional fields to an event schema without breaking older consumers.
Anti-Patterns for Event Sourcing with Kafka
1Treating Kafka as a Database
- Anti-Pattern: Using Kafka to store and query event data directly as a primary database.
- Why it’s problematic:
- Kafka is optimized for streaming and not designed for random access or querying historical data.
- High retention and large event logs can lead to increased storage and operational costs.
- Solution: Use a database to store materialized views of event data for querying.
2Ignoring Event Ordering
- Anti-Pattern: Producing events to multiple partitions without a consistent key, leading to out-of-order events for the same entity.
- Why it’s problematic:
- Consumers may see updates (e.g., OrderShipped) before creates (e.g., OrderCreated).
- Solution: Always use a consistent partition key (e.g., entity ID) to maintain order.
3Overusing Log Compaction
- Anti-Pattern: Applying log compaction to all topics, including those where historical event data is needed.
- Why it’s problematic:
- Log compaction removes older events, making it impossible to replay the full event history.
- Solution: Use compaction only for topics that require the latest state, and use infinite retention for event logs.
4Creating Large, Monolithic Events
- Anti-Pattern: Storing large payloads or multiple changes in a single event.
- Why it’s problematic:
- Increases latency and resource consumption for producers and consumers.
- Harder to track granular changes in the system.
- Solution: Design small, granular events representing individual state changes.
5Neglecting Dead Letter Topics
- Anti-Pattern: Failing to handle invalid or unprocessable events.
- Why it’s problematic:
- Causes consumers to crash or skip messages without tracking errors.
- Solution: Use a dead letter topic to store problematic events and review them later.
6Missing Idempotence in Producers
- Anti-Pattern: Sending duplicate events without idempotence enabled.
- Why it’s problematic:
- Leads to duplicate processing and incorrect state updates.
- Solution: Enable enable.idempotence=true in Kafka producer configurations.
7Not Monitoring Event Lag
- Anti-Pattern: Ignoring consumer lag or failing to monitor it.
- Why it’s problematic:
- Consumers may fall behind, causing delayed processing of events.
- Solution: Monitor consumer lag using tools like Kafka Consumer Lag Exporter or Prometheus.
6. Overcoming Kafka Scaling Challenges: Lessons from the Real World
As organizations increasingly rely on Apache Kafka to handle high-throughput, real-time data pipelines, scaling Kafka to meet growing demands becomes both a necessity and a challenge. While Kafka is built for scalability and fault tolerance, managing it at scale comes with its own set of hurdles, such as partition imbalances, consumer lag, and replication bottlenecks.
In this section, we’ll dive into some real-world challenges companies have faced when scaling Kafka and explore the practical solutions they implemented. By learning from these experiences, you can proactively address common issues and ensure your Kafka deployment remains efficient, resilient, and ready to handle enterprise-scale workloads.
1Partition Imbalance
Partition imbalance in Kafka happens when data isn’t evenly distributed across partitions, and some brokers carry a heavier load than others. It’s like having a few team members doing all the work while others sit idle, it’s unfair and inefficient. This imbalance can lead to high CPU usage, memory issues, or even slower performance on the overloaded brokers, while the others are barely being used.
It’s a common challenge, especially when traffic increases or partition planning wasn’t done with scaling in mind. Fixing it often means rebalancing partitions, which can be tricky and disruptive if not handled properly. That’s why understanding how to prevent or manage partition imbalance is so important to keep your Kafka cluster running smoothly.


Solution
Out of the box, Kafka does not provide full self-balancing for partition distribution, broker workload, and traffic. However, it does offer basic rebalancing mechanisms, such as:
- Consumer Group Rebalancing – Automatically redistributes partitions when a consumer joins or leaves.
- Partition Reassignment Tool – Manual rebalancing via kafka-reassign-partitions.sh.
- Rack Awareness – Helps distribute partitions across different racks for fault tolerance.
However, these mechanisms do not fully optimize broker load, disk usage, or partition leadership balancing automatically. This is where tools like Cruise Control comes in.
Cruise Control
Cruise Control (CC) is an open-source tool developed by LinkedIn to automate partition balancing, broker load optimization, and self-healing in Kafka. It helps rebalance partitions across brokers to avoid hotspots, ensure high availability, and improve overall cluster efficiency.
following are some of the key features of the cruise control
- Automated Partition Balancing – Redistributes partitions based on CPU, disk, and network utilization.
- Self-Healing – Detects broker failures and reassigns partitions automatically.
- Anomaly Detection – Identifies under-replicated partitions, offline replicas, and imbalanced workloads.
- Broker Auto-Scaling – Balances partitions when brokers are added or removed.
- Throttled Execution – Ensures rebalancing does not disrupt real-time Kafka operations.

Let’s quickly look at the components of Cruise Control
- Rest API (User Interaction)
The user interacts with Kafka Cruise Control through its REST API. It is the entry point for managing and monitoring Kafka clusters through Cruise Control. This API allows users to- Request load monitoring (/kafkacruisecontrol/load)
- Trigger rebalancing (/kafkacruisecontrol/rebalance)
- View optimization proposals (/kafkacruisecontrol/proposals)
- Check for anomalies and failures (/kafkacruisecontrol/anomaly_detector_state)
- Analyzer (Optimization Engine)
The Analyzer uses these goals to evaluate the cluster’s health and decide how to rebalance it. Goals are the rules and constraints that define what an optimized Kafka cluster should look like.The Analyzer in Kafka Cruise Control plays a dual role
- Manual Triggered Analysis:
- It receives explicit requests from the REST API when a user triggers operations like rebalancing, optimization proposals, or cluster load evaluations.
- Example: A user calls the /rebalance endpoint to optimize the cluster after adding new brokers.
- Automated Anomaly Detection and Self-Healing:
- The Analyzer also works autonomously by responding to alerts from the Failure Detector.
- It automatically triggers the Analyzer to generate a corrective action without any manual intervention.
- Manual Triggered Analysis:
- Failure Detector
The Failure Detector continuously monitors the Kafka cluster for anomalies like
- Broker failures
- Disk failures
- Under-replicated partitions
- Offline replicas
- Workload Monitor (Real-Time Metrics Collection)
The Workload Monitor provides the data necessary for the Analyzer to evaluate cluster health and optimization. It collects real-time metrics from the Kafka cluster using the Metric Sampler. Sampler fetches the metrics via Kafka Metrics Reporter (default) or Prometheus integration (optional). These metrics include
- CPU usage
- Disk utilization
- Network throughput
- Partition distribution
- Executor (Action Engine)
The Executor is responsible for executing the rebalancing plan in a controlled and throttled manner to minimize the impact on Kafka performance.Once the Analyzer generates an optimization plan, the Executor carries out the partition movements, leadership changes, or replica reassignments to balance the cluster.
Here’s the corrected and completed version of your sentence:
Before we wrap up the topic of Cruise Control, I’d like to give a brief overview of the goals used by the Analyzer, as understanding these is crucial. If you ever plan to develop your own tool instead of using Cruise Control, having a solid grasp of these goals will be highly beneficial. They define the optimization rules and constraints that ensure your Kafka cluster remains balanced, efficient, and resilient.
Types of Goals in Kafka Cruise Control
- Hard Goals:
- Must be satisfied during any rebalancing process.
- If a hard goal cannot be met, Cruise Control will fail the rebalance.
- Example: RackAwareGoal ensures replicas are distributed across different racks for fault tolerance.
- Soft Goals:
- Best-effort goals that Cruise Control tries to satisfy but can compromise if needed.
- Example: NetworkInboundUsageDistributionGoal ensures even network usage but may be sacrificed if disk capacity constraints are stricter.

2Consumer Lag
Imagine you’re at a buffet (because who doesn’t love food analogies?), and the chef (that’s the Kafka producer) is constantly adding fresh dishes to the table. Now, you’re the consumer—grabbing plates and eating. Consumer lag happens when the chef is adding food faster than you can eat. So, there’s this growing pile of dishes you haven’t gotten to yet. That gap? That’s consumer lag.
Consumer Lag refers to the difference between the latest message available in a Kafka partition and the latest message processed by a consumer. It essentially measures how far behind a consumer is from the latest data being produced to the Kafka topic.
In simple terms, consumer lag tells us whether a consumer is processing messages in real-time or if it’s falling behind.

Why Should You Care About Consumer Lag?
If you’re running something like a real-time dashboard or a fraud detection system, lag is your enemy. High consumer lag means your system is processing stale data. Imagine getting an alert about fraud 5 minutes after it happened, not very helpful, right?
But if you’ve got zero lag, it means your consumers are munching through the data as fast as it’s coming in. Everything’s fresh, real-time, and snappy.
How Does Kafka Measure Consumer Lag?
Kafka keeps track of this lag by comparing two numbers:
- Latest Offset: This is like the chef’s last dish on the table (the most recent message produced).
- Current Offset: This is the last plate you’ve eaten (the most recent message the consumer has processed).
Consumer Lag = Latest Offset – Current Offset
If the latest message is at #1050 and your consumer is at #1000, your lag is 50 messages.
What Causes Kafka Consumer Lag?
Alright, let’s dig into what actually causes consumer lag in Kafka. Think of consumer lag like being stuck in traffic—you want to be cruising along smoothly, but sometimes things just slow you down. Here’s why that happens in the Kafka world
- Slow Consumer Processing
Your consumer is taking too long to process each message. This could be due to heavy computations, waiting on external APIs, or writing to slow databases.
Example: Imagine a consumer that processes financial transactions and checks for fraud. If it has to run complex fraud detection algorithms for every single message, it’ll naturally fall behind.
How to Fix It:- Batch processing: Instead of handling one message at a time, process them in chunks.
- Offload to other services: Use background workers or async processes to handle slower tasks.
- Not Enough Consumers (Insufficient Parallelism)
You have more data than your consumers can handle because you’re not using enough consumers or partitions to spread the load.
Example: Let’s say you have one consumer handling a topic with 10 partitions. That consumer is doing all the work while the other potential consumers are just chilling.
How to Fix It:- Add more consumers to the consumer group. Kafka will automatically balance the load.
- Increase the number of partitions in your topic to allow more parallel processing.
- Network Latency and Bandwidth Issues
The connection between your Kafka brokers and consumers is slow. Maybe you’re pulling data across data centers or dealing with network congestion.
Example: If your Kafka brokers are in one cloud region and your consumers are in another, the data has to travel farther, which slows things down.
How to Fix It:- Deploy consumers closer to your brokers (same region or even the same data center).
- Optimize network configurations to reduce latency and increase throughput.
- Use rack awareness in Kafka to reduce cross-rack traffic.
- Misconfigured Consumer Settings
Kafka consumer configurations aren’t optimized, causing it to fetch or process messages inefficiently.
Common Config Issues and fix:
fetch.min.bytesis too low:- The consumer fetches tiny amounts of data, making too many trips
- Increase
fetch.min.bytesandmax.partition.fetch.bytesto pull more data at once.
max.poll.recordsis small:- The consumer processes too few messages per poll
- Raise max.poll.records to process more messages per poll
max.poll.interval.msis too short:- If your processing takes longer, Kafka thinks the consumer is dead and rebalances
- Adjust max.poll.interval.ms to give consumers enough time to process messages.
- Broker Bottlenecks (Kafka Itself is Struggling)
Sometimes the problem isn’t with the consumer—it’s with Kafka brokers being overloaded. If Kafka can’t deliver messages fast enough, your consumer lags.
Example: If one broker is handling too many partitions (a partition imbalance), it can become a hotspot, slowing down message delivery.
How to Fix It- Use Kafka Cruise Control to rebalance partitions across brokers.
- Optimize broker configurations like num.network.threads and num.io.threads.
- Scale out your Kafka cluster by adding more brokers.
- Frequent Consumer Group Rebalancing
When consumers join or leave the consumer group frequently, Kafka triggers a rebalance. During this time, consumers pause message processing.
Example: If your consumers are running in containers (like in Kubernetes) and they restart often, you’ll see frequent rebalancing, leading to gaps in processing.
How to Fix It:- Use static membership to reduce unnecessary rebalancing, ie, assign a static consumer id
group.instance.id=consumer-1 - Increase the session timeout to give consumers more time before Kafka kicks off a rebalance –
session.timeout.ms=15000
- Use static membership to reduce unnecessary rebalancing, ie, assign a static consumer id
- Resource Constraints (CPU, Memory, Disk)
Your consumers are starved for resources—they don’t have enough CPU, memory, or disk I/O to process messages quickly.
Example: If your consumer is running on a shared server with other resource-hungry applications, it might not get the power it needs to keep up.
How to Fix It:- Allocate more CPU and memory to your consumer application.
- Optimize JVM settings if you’re running Kafka consumers in Java to reduce GC (Garbage Collection) pauses –
-Xms2G -Xmx2G -XX:+UseG1GC - Run your consumers on dedicated servers or containers.
- External Dependencies Are Slow (Databases, APIs, etc.)
Your consumers rely on external systems (like databases, REST APIs, or third-party services) that are slow to respond, causing processing delays.
Example:Imagine a consumer that reads messages and writes them to a slow SQL database. If the database starts lagging, so will your consumer.
How to Fix It:- Batch write operations to the database instead of writing one record at a time.
- Use caching for repetitive API calls.
- Offload slow operations to asynchronous processes or background workers.
- Retention Policies and Log Compaction Delays
Kafka’s retention settings might delete messages before slow consumers can process them. Or, log compaction might slow down data retrieval for certain topics.
Example: If your retention period is set to 1 hour but your consumer is lagging behind by 2 hours, Kafka will delete those older messages, and the consumer will miss them entirely.
How to Fix It:- Increase the retention period for your topics to give consumers more time to catch up.
log.retention.hours=168 # Retain data for 7 days
- Optimize log compaction settings if you’re using compacted topics
log.cleaner.threads=4log.cleaner.io.max.bytes.per.second=10485760
- Increase the retention period for your topics to give consumers more time to catch up.
- Security Overhead (SSL/SASL)
Using SSL encryption or SASL authentication adds a layer of overhead, which can slow down both brokers and consumers.
Example: If you’re using SSL/TLS with inefficient configurations, the encryption process can hog CPU resources, slowing down message consumption.
How to Fix It:- Optimize SSL configurations like
ssl.endpoint.identification.algorithmandssl.engine.factory.class - Ensure SASL authentication mechanisms are set up efficiently to reduce re-authentication overhead by increasing the session timeouts.
- Optimize SSL configurations like


